
Let’s have a look at the different ways to run Spring Boot 3 applications on AWS Lambda using the following frameworks, technologies, and tools:
- AWS Serverless Java Container
- AWS Lambda Web Adapter
- Spring Cloud Function
- Customised Docker Image
First things first, we’ll introduce the concept behind it and learn how to develop, deploy, and operate our application with the respective approach. We’ll also look at GraalVM Native Image using Spring Cloud Function as an option deployed as an AWS Lambda Custom Runtime. Last but not least, we will investigate if native support for Coordinated Restore at Checkpoint (CRaC) in Spring Boot 3 is also a valid approach.
Of course, we’ll measure the Lambda function’s cold and warm start times with all of the aforementioned approaches and evaluate the solutions. We’ll also see how we can optimise cold starts for the Lambda functions with SnapStart (including various priming techniques) – if it is a feasible solution for the respective approach (currently not available for the Docker container images). Code examples for the entire series are available on my GitHub account.
Introduction
The AWS Serverless Java Container facilitates the execution of Java applications written with frameworks like Spring, Spring Boot 2 and 3, or JAX-RS/Jersey in Lambda. The container offers adapter logic to minimise code changes. Incoming events are translated into the servlet specification so that the frameworks can be used as before (Fig. 1)
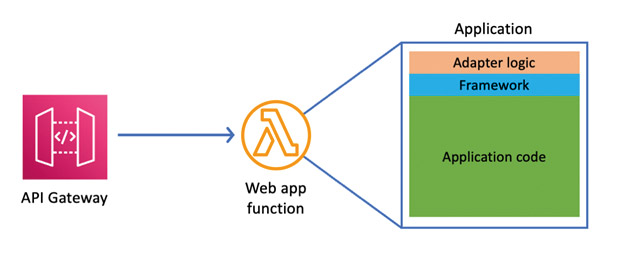
Fig. 1: AWS Serverless Java Container architecture
AWS Serverless Java Container provides the core container and framework-specific containers such as the one for Spring Boot 3, which is the focus of this article. There are also other containers for the Spring, Struts, and Jersey frameworks. A major update to version 2.0 was recently released for all AWS Serverless Java Containers. The dependency tree denotes another dependency spring-cloud-function-serverless-web, which needs the artefact aws-serverless-java-container-springboot3. This is because of the collaboration between Spring and AWS serverless developers and offers Spring Cloud Function on AWS Lambda functionality. (The possibilities of this will be discussed in an upcoming entry to this AWS Lambda series.)
AWS Serverless Java Core Container also provides abstractions such as AWSProxyRequest/Response for mapping API gateway (REST) requests to the servlet model including various authorisers such as Amazon Cognito and HttpApiV2JwtAuthorizer. In the core container, everything is passed through the AwsHttpServletRequest/Response abstractions or their derivatives like AwsProxyHttpServletRequest.
My personal preference is that a subset of abstractions from the Java package com.amazonaws.serverless.proxy.model, such as
- AwsProxyRequest
- ApiGatewayRequestIdentity
- AwsProxyRequestContext
- AwsProxyResponse
and others become part of a separate project and can be used without using all the other AWS Serverless Java Container APIs just for mocking the API Gateway Request/Response (i.e. priming). In an upcoming entry, we’ll directly use these abstractions when we look at cold and warm start time improvements for Spring Boot 3 applications on AWS Lambda using AWS Lambda SnapStart together with priming techniques. An introduction to AWS Lambda SnapStart can be found in Java Magazin 10.2023.
The Lambda Runtime has to know which handler method will be called. The AWS Serverless Spring Boot 3 container, which internally uses the AWS Serverless Java Core container, simply adds some implementations, such as SpringDelegatingLambdaContainerHandler. We can also implement our own Java handler class that delegates to the AWS Serverless Java container. This is useful if we want to implement extra functions like the Lambda SnapStart priming technique. The SpringBootLambdaContainerHandler abstraction (which inherits the AwsLambdaServletContainerHandler class from the core container) can be used by passing the main Spring Boot class annotated with @SpringBootApplication as input. For Spring Boot 3 applications that take longer than ten seconds to start, there is an asynchronous way to create SpringBootLambdaContainerHandlers by using the SpringBootProxyHandlerBuilder abstraction. Since version 2.0.0’s release, it always runs asynchronously by default. Previously, we had to call the asyncInit method (which is now deprecated) to initialise SpringBootProxyHandlerBuilder asynchronously. I’ll explain this in more detail later using code examples.
STAY TUNED!
Learn more about Serverless Architecture Conference
Developing the application
To explain this, we use our Spring Boot 3 example application and the Java 21 runtime for our lambda functions (Fig. 2).
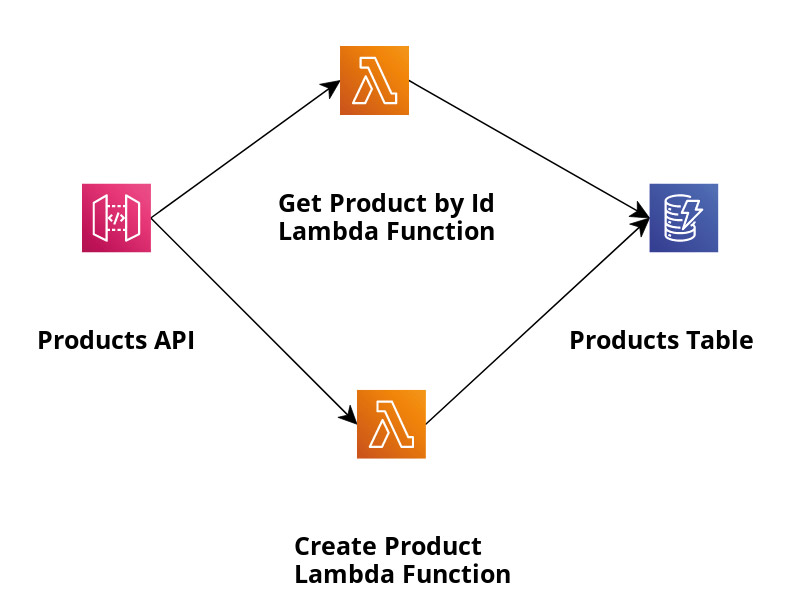
Fig. 2: The demo application’s architecture
In this application, we’ll create products and retrieve them by their ID, using Amazon DynamoDB as a NoSQL database for the persistence layer. We use Amazon API Gateway, which makes it easy for developers to create, publish, maintain, monitor, and secure APIs. AWS SAM will also be used, which provides a short syntax optimised for the definition of Infrastructure as Code (hereafter IaC) for serverless applications. You can find the full code of Product Controller (ProductController class), DynamoDB persistence logic (DynamoProductDAO class), request stream handler implementation (StreamLambdaHandler class) and IaC based on AWS SAM (template.yaml) in my GitHub repository.
To build this application, we need to run the mvn clean package. To deploy it, we need to run sam deploy -g in the directory where the SAM template (template.yaml) is located. We receive the individual Amazon API Gateway URL as a return. We can use it to create products and retrieve them according to their ID. The interface is secured with the API key (we have to send the following as HTTP header: “X-API-Key: a6ZbcDefQW12BN56WEA7”). To create the product with the ID 1, we have to send the following query with Curl, for example:
curl -m PUT -d ‘{ “id”: 1, “name”: “Print 10×13”, “price”: 0.15 }‘ -H “X-API-Key: a6ZbcDefQW12BN56WEA7” https://{$API_GATEWAY_URL}/prod/products
To query the existing product with ID 1, the following curl query must be sent:
curl -H “X-API-Key: a6ZbcDefQW12BN56WEA7” https://{$API_GATEWAY_URL}/prod/products/1
Now, let’s look at the relevant source code fragments. The Spring Boot 3 ProductController class, annotated with @RestController and @EnableWebMvc defines the methods getProductById and createProduct (Listing 1).
Listing 1
@RequestMapping(path = "/products/{id}", method = RequestMethod.GET, produces = MediaType.APPLICATION_JSON_VALUE) public Optional<Product> getProductById(@PathVariable(„id“) String id) { return productDao.getProduct(id); } @RequestMapping(path = "/products/{id}", method = RequestMethod.PUT, consumes = MediaType.APPLICATION_JSON_VALUE) public void createProduct(@PathVariable(„id“) String id, @RequestBody Product product) { product.setId(id); productDao.putProduct(produkt); }
The main dependency for the function and translation between the Spring Boot 3 model (web annotation) and AWS Lambda is the dependency on the artefact aws-serverless-java-container-springboot3, which is defined in the pom.xml:
<dependency>
<groupId>com.amazonaws.serverless</groupId>
<artifactId>aws-serverless-java-container-springboot3</artifactId>
<version>2.0.0</version>
</dependency>
It is based on the Serverless Java Container, which natively supports the API Gateway’s proxy integration models for requests and responses. We can create and inject custom models for methods that use custom mappings.
The easiest way to tie everything together is to define a generic SpringDelegatingLambdaContainerHandler from the aws-serverless-java-container-springboot3 artefact in the AWS SAM template (template.yaml). We’ll also pass the main class of our Spring Boot application (the class annotated with @SpringBootApplication ) as the MAIN_CLASS environment variable (Listing 2).
Listing 2
Handler: com.amazonaws.serverless.proxy.spring.SpringDelegatingLambdaContainerHandler Environment: Variables: MAIN_CLASS: com.amazonaws.serverless.sample.springboot3.Application
SpringDelegatingLambdaContainerHandler stands in as the proxy, receiving all requests and forwarding them to the correct method of our Spring Boot Controller (ProductController class).
Another way to tie everything together is to implement our own request stream handler (StreamLambdaHandler class), which implements the com.amazonaws.services.lambda.runtime.RequestStreamHandler interface to define it in the AWS SAM template (template.yaml) (Listing 3).
Listing 3
Globals: Function: Handler: software.amazonaws.example.product.handler.StreamLambdaHandler::handleRequest
As a user-defined generic proxy, StreamLambdaHandler receives all requests and forwards them to the correct method of our Spring boot controller (ProductController class). First, in the StreamLambdaHandler, we instantiate the SpringBootLambdaContainerHandler:
SpringBootLambdaContainerHandler<AwsProxyRequest, AwsProxyResponse> handler = SpringBootLambdaContainerHandler.getAwsProxyHandler(Application.class);
We’ve given Application.class, the main class of our Spring Boot application (the class annotated with @SpringBootApplication ), as a parameter when instantiating the handler.
In the following excerpt from the StreamLambdaHandler class, the input stream is forwarded to the designated method of the handler’s product controller:
@Override
public void handleRequest(InputStream inputStream, OutputStream outputStream, Context context) throws IOException {
handler.proxyStream(inputStream, outputStream, context);
}
If we want to implement our own logic, this approach is the preferred method. The next part of this series will show why with Lambda SnapStart Priming.
Now, we’ve looked at all the relevant parts of the source code of the Spring Boot 3 application on AWS Lambda with AWS Serverless Java Container. We also learned how everything works together. Let’s look at cold and warm start metrics and see how we can optimise the cold start.
Measuring strategies for cold and warm starts
For a good overview of cold start in AWS serverless applications, AWS Lambda SnapStart, pre- and post-snapshot hooks (based on CRaC) and priming techniques. See my article in Java Magazin 10.2023 and my article series on dev.to. We’ll build upon these concepts in the following steps.
We want to measure the cold and warm start of the lambda function named GetProductByIdWithSpringBoot32 (see template.yaml for the mapping), which determines products based on an ID, for four different cases:
- without activation of AWS (Lambda) SnapStart
- with activation of AWS (Lambda) SnapStart, but without the application of priming
- with activation of AWS (Lambda) SnapStart and the application of priming of a DynamoDB request
- with activation of AWS (Lambda) SnapStart and with application of local priming/proxying of the entire web request
Let’s go through all four cases individually and see what we need to consider.
Without activating AWS (Lambda) SnapStart
We can use the code in the IaC template, based on AWS SAM (template.yaml) in Listing 2 or 3 for this. SnapStart will not be activated in the default variant.
With activation of AWS (Lambda) SnapStart, but without the application of priming
We can adopt the code in the IaC template, based on AWS SAM (template.yaml) in Listing 2 or 3, but we must also activate SnapStart on the Lambda functions, as shown in Listing 4.
Listing 4
Globals: Function: Handler: software.amazonaws.example.product.handler.StreamLambdaHandler::handleRequest SnapStart: ApplyOn: PublishedVersions
With activation of AWS (Lambda) SnapStart and priming of the DynamoDB request
In this case, the IaC based on AWS SAM (template.yaml) looks like Listing 5.
Listing 5
Globals: Function: Handler: software.amazonaws.example.product.handler. StreamLambdaHandlerWithDynamoDBRequestPriming::handleRequest SnapStart: ApplyOn: PublishedVersions
Activate SnapStart for lambda functions and use the specially written Lambda-RequestStreamHandler implementation called StreamLambdaHandlerWithDynamoDBRequestPriming. This also performs DynamoDB request priming (based on CRaC). Listing 6 shows the relevant class’ source code.
Listing 6
public class StreamLambdaHandlerWithDynamoDBRequestPriming implements RequestStreamHandler, Resource { private static final ProductDao productDao = new DynamoProductDao(); ... public StreamLambdaHandlerWithDynamoDBRequestPriming () { Core.getGlobalContext().register(this); } ... @Override public void beforeCheckpoint(org.crac.Context<? extends Resource> context) throws Exception { productDao.getProduct("0"); } ... }
The class implements the interface org.crac.Resource and registers itself as a CRaC resource in the constructor. Priming occurs in the beforeCheckpoint method, where we ask DynamoDB for the product with the ID 0. This means that most of the call to the lambda function named GetProductByIdWithSpringBoot32 (see template.yaml for mapping) is primed.
We’re not interested in the result at all. This call instantiates all required classes and the expensive one-time initialisation of the HTTP client (default is the Apache HTTP client) and the Jackson Marshall (for the purpose of converting Java objects to JSON and vice versa) is carried out. Since this happens during the Lambda function’s deployment phase when SnapStart is activated and before the snapshot is created, the snapshot will already contain all of this. After the fast snapshot recovery during the lambda call, we gain a lot of performance by priming in case of a cold start (see measurements below).
With activation of AWS (Lambda) SnapStart and application of local priming/proxying of the entire web request
In this case, the IaC based on AWS SAM (template.yaml) looks like Listing 7.
Listing 7
Globals: Function: Handler: software.amazonaws.example.product.handler. StreamLambdaHandlerWithWebRequestPriming::handleRequest SnapStart: ApplyOn: PublishedVersions
We enable SnapStart for Lambda functions and use the custom written Lambda RequestStreamHandler implementation called StreamLambdaHandlerWithWebRequestPriming, which also performs local priming/proxying of the whole web request (based on CRaC). In doing so, we create the JSON code normally used by the Amazon API Gateway to call Lambda functions (in our case, the Lambda function that queries products by ID from the DynamoDB), but everything happens locally without network communication. Listing 8 shows the class’ relevant source code..
Listing 8
public class StreamLambdaHandlerWithWebRequestPriming implements RequestStreamHandler, Resource { private static SpringBootLambdaContainerHandler<AwsProxyRequest, AwsProxyResponse> handler; static { try { handler = SpringBootLambdaContainerHandler.getAwsProxyHandler(Application.class); } catch (ContainerInitializationException e) { ... } } ... public StreamLambdaHandlerWithWebRequestPriming () { Core.getGlobalContext().register(this); } ... @Override public void beforeCheckpoint(org.crac.Context<? extends Resource> context) throws Exception { handler.proxyStream(new ByteArrayInputStream(getAPIGatewayRequest().getBytes(StandardCharsets.UTF_8)), new ByteArrayOutputStream(), new MockLambdaContext()); } ... private static AwsProxyRequest getAwsProxyRequest () { final AwsProxyRequest awsProxyRequest = new AwsProxyRequest (); awsProxyRequest.setHttpMethod("GET"); awsProxyRequest.setPath("/products/0"); awsProxyRequest.setResource("/products/{id}"); awsProxyRequest.setPathParameters(Map.of("id","0")); final AwsProxyRequestContext awsProxyRequestContext = new AwsProxyRequestContext(); final ApiGatewayRequestIdentity apiGatewayRequestIdentity= new ApiGatewayRequestIdentity(); apiGatewayRequestIdentity.setApiKey("blabla"); awsProxyRequestContext.setIdentity(apiGatewayRequestIdentity); awsProxyRequest.setRequestContext(awsProxyRequestContext); return awsProxyRequest; } ... }
The class also implements the org.crac.Resource interface and registers itself as a CRaC resource in the constructor. The getAwsProxyRequest method creates the minimalist web request using the AwsProxyRequest abstraction from the AWS Java Serverless Core Container. We pass the HTTP method (GET) and the path (/product/0) to query the product with the ID 0 from the DynamoDB.
Priming itself occurs in the beforeCheckpoint method. This is where we convert the result of the getAwsProxyRequest method into ByteArrayInputStream and the SpringBootLambdaContainerHandler uses it as a proxy. This internally calls the lambda function named GetProductByIdWithSpringBoot32 (see template.yaml for the mapping), which makes the DynamoDB call (and its priming). This type of priming causes a lot of extra code, which can be significantly simplified with a few utility methods. The decision to use priming is left to us, the developers.
The goal of priming is to instantiate all the required classes and translate the Spring Boot 3 programming model (and the call) into the AWS Lambda programming model (and the call) using the AWS Serverless Java Container for Spring Boot 3. The expensive one-time initialisation of the HTTP client (default is the Apache HTTP client) and the Jackson Marshall (for the purpose of converting Java objects to JSON and vice versa) is also carried out. Since this is done during the Lambda function’s deployment phase when SnapStart is activated and before the snapshot is created, the snapshot will already contain all of this. After the quick snapshot recovery during the Lambda call, we gain a lot of performance by priming in case of cold start (see measurements below).
Presentation of the measurement results of cold and warm starts
The results of the following experiment are based on the reproduction of more than 100 cold starts and around 100,000 warm starts with the lambda function for the duration of one hour. I used the hey load test tool, which is very similar to CURL. But you can use any other tool, like Serverless Artillery or Postman.
Allocate 1024 MB of memory to our Lambda function and use the Java compilation option XX:+TieredCompilation -XX:TieredStopAtLevel=1, which can be assigned to the Lambda function with the environment variable JAVA_TOOL_OPTIONS. This is a good choice for the relatively short-lived lambda functions (Fig. 3). Alternatively, we can also omit the JAVA_TOOL_OPTIONS variable in template.yaml. Then, the default compilation option “tiered compilation” will take effect and produce very good results.
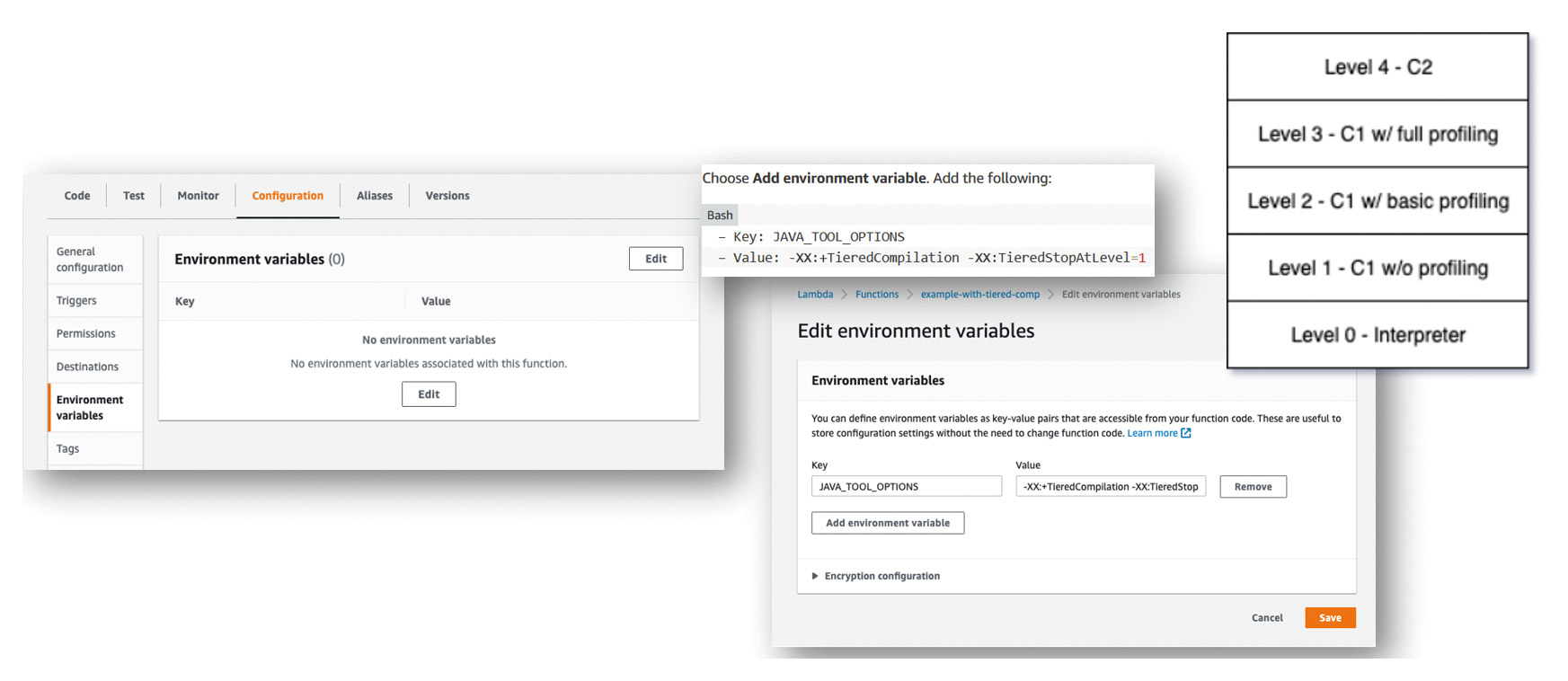
Fig. 3: Setting the environment variable JAVA_TOOL_OPTIONS with the compilation option of a lambda function
Table 1 shows the measurement results in milliseconds. The abbreviation C stands for cold start and W for warm start. The numbers after this are percentiles. Please note that you must do this yourself for your own use case and you may get (slightly) different results. This can happen for the following reasons:
- Minor version change to the runtime environment managed by Lambda Amazon Corretto Java 21
- Improvements creating and restoring Lambda SnapStart snapshots
- Improvements to the Firecracker VM
- Impact of the Java memory model (hit and miss L or RAM caches)
Table 1: The measurement results
Just by enabling AWS Lambda SnapStart for the Lambda function, its cold start time is significantly reduced. By also using DynamoDB call priming and especially local priming/proxying for the web request (however, I don’t recommend using this technique in production), we achieved cold starts with measured values only slightly higher than the cold starts for the Lambda-only function without using frameworks. The warm start execution times are also reasonably higher than those measured for the pure lambda function without using frameworks.
Please note the effect of the AWS Snapstart snapshot tiered cache. For SnapStart activation, we mainly get the largest cold start values in the first measurements. Subsequent cold starts have lower values due to the tiered cache. Since I showed the cold starts of the first 100 versions after the Lambda version was published in the table, all cold starts from around the 50th version in the C50 to C90 range are significantly lower. For further details about the technical implementation of AWS SnapStart and its tiered cache, I refer to Mike Danilov’s presentation: “AWS Lambda Under the Hood”.
Conclusion
In this article, we looked at AWS Serverless Java Container and its architecture and explained how we can implement a Spring 3 application on AWS Lambda with the Java 21 runtime environment using AWS Serverless Java Container. We saw that we can largely reuse the existing Spring Boot 3 application completely. We need specially written Lambda functions, especially when activating the AWS Lambda SnapStart and using priming techniques. We also measured cold and warm starts for our lambda functions. We looked at optimisations with AWS Lambda SnapStart, including priming techniques that significantly reduce the lambda function’s cold start.
In the next part of this series, I’ll introduce the AWS Lambda Web Adapter tool. We’ll learn how to develop the Spring Boot 3 application based on this tool and see how to run and optimise it on AWS Lambda.




