
AWS Proton is a fully managed service for rolling out container and serverless applications. Platform engineering teams can use AWS Proton to connect and coordinate all of the various tools required for infrastructure provisioning, code deployment, monitoring, and updates. Proton resolves this by giving platform teams the tools they need to manage these complex processes and enforce consistent standards, while making it easier for developers to deploy code with containers and serverless technologies (Figure 1).
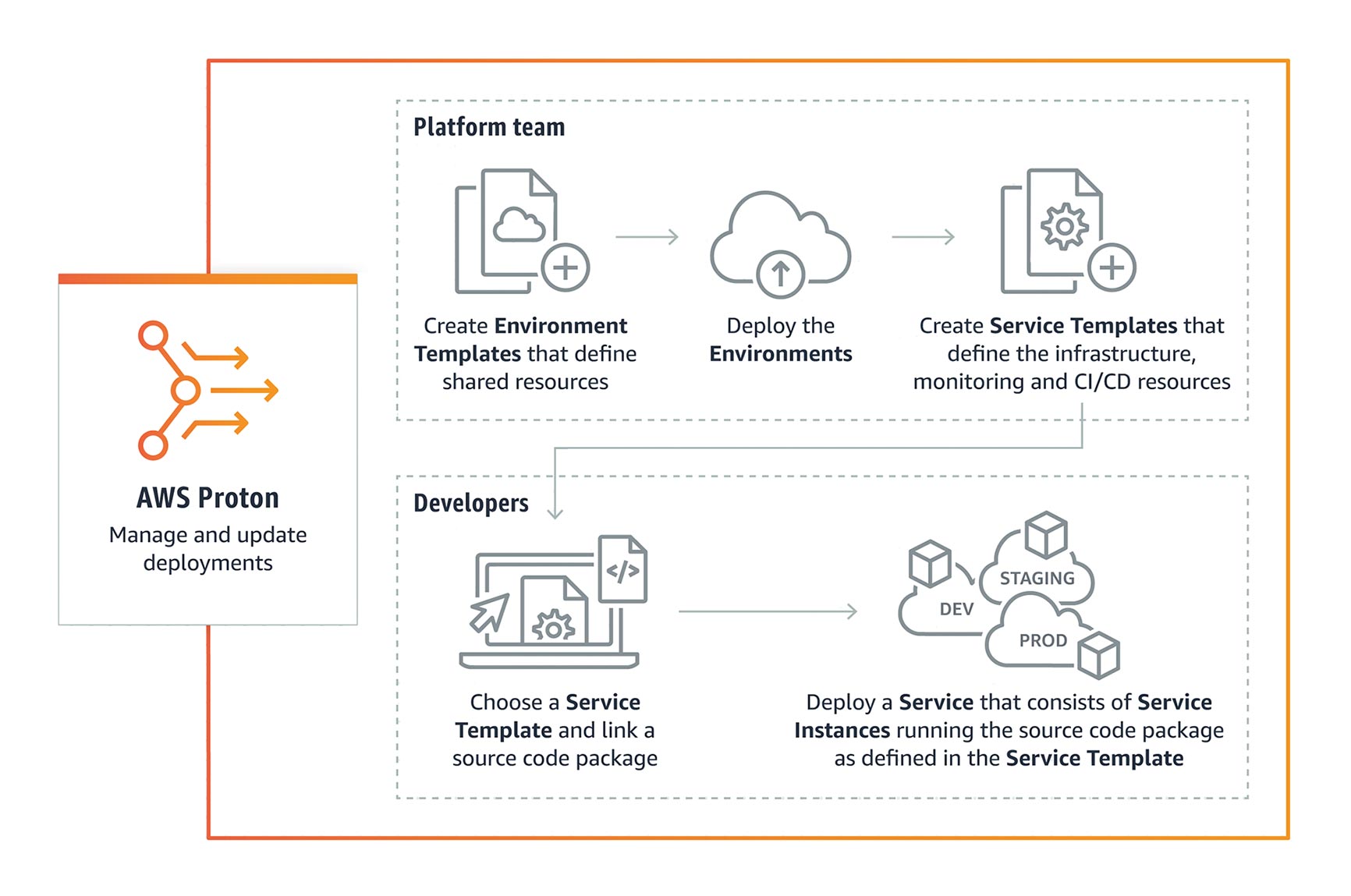
Fig. 1: The AWS Proton workflow
One typical pattern seen in large companies is having development teams that implement the actual functionalities, in addition to the platform teams. Developers work with platform teams to define and build infrastructure configurations and package all of the necessary files for deployment. Every time the developers want to change something, the full cycle needs to be repeated with the platform team so they can maintain consistency and control over all services.
A popular approach used in large companies is building a shared service platform or an internal developer platform. Platform teams use AWS Proton to create a stack defining everything they need to provision, deploy, and monitor a service. Developers log into the AWS Proton Console and use published AWS Proton Stacks to automate infrastructure provisioning and quickly deploy their application code. Instead of spending hours setting up infrastructure for each development team, platform or operations teams can manage deployments centrally. When part of the stack needs to be updated, the platform team uses AWS Proton to deploy updates to existing microservices that could have outdated configurations.
Learn more about Serverless Architecture ConferenceSTAY TUNED!
What are template bundles?
AWS Proton infrastructure template bundles can be created for automatic application deployment. Template bundles contain all of the information that AWS Proton needs to provision and manage the version-controlled Infrastructure as Code resources in an automatic, transparent, and repeatable manner. After a template bundle is created, it becomes a part of the versioned AWS Proton template library.
Administrators can be provided with all of the information that AWS Proton needs in the following YAML formatted files, which make up a template bundle:
- Infrastructure template files with a manifest file listing the template files
- A schema file that defines the parameters that can be used and shared by the template files and the resources which they provide
AWS Proton manages and provisions infrastructure resources across environments, services, service instances, and optional CI/CD service pipelines. Environments represent a network of shared resources that administrators or developers use to deploy service instances. Service instances run the developer’s applications. When developers select a versioned service template bundle from the library, AWS Proton uses it to deploy and manage the applications.
The diagram in Figure 2 shows a process for creating a template bundle that can be used to define infrastructure resources for an environment or service.
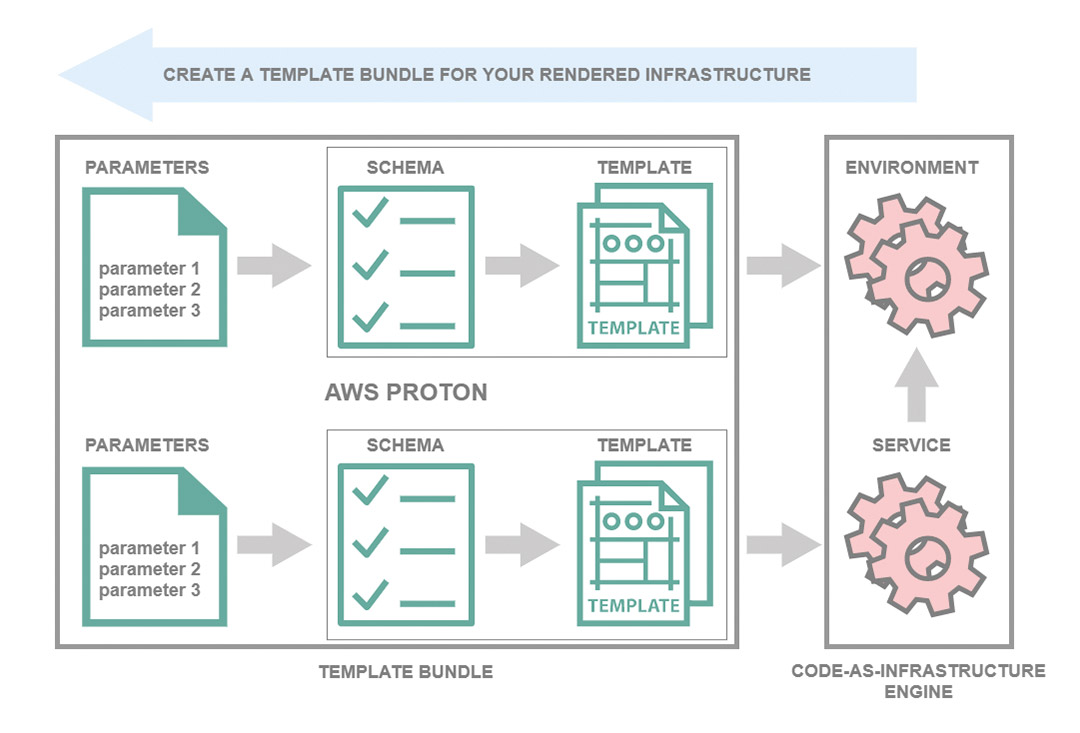
Fig. 2: Schematic representation of the template bundle structure
Customization parameters are parameters that can be added to infrastructure templates in order to make them flexible and reusable. In a service infrastructure template file, a namespace must be attached to a customization parameter in order to link it with an AWS Proton resource. You can only specify values for these parameters when creating the service. The following list contains examples of customization parameters for some typical use cases:
- Port
- Task Size
- Image
- Required number
- Dockerfile
- Unit test
After these parameters are identified, you must define a schema to serve as the interface for customization parameters between AWS Proton and the infrastructure template files. The schema is then used when defining parameters while creating the infrastructure’s template.
Administrators or developers specify values for customization parameters when they use a service template to create a service. When they use the console to create a service, AWS Proton automatically provides a schema-based form to fill out. When the CLI is used, a specification must be provided that contains values for the customization parameters. Resource-based parameters are linked with AWS Proton resources. For example, if a resource defined in one template file needs to be referenced in another template file, a namespace can simply be added, linking it to an AWS Proton resource.
The template bundle’s main components are template files for the infrastructure or configuration files that define the infrastructure resources and properties to be provided. AWS CloudFormation and other Infrastructure as Code engines use these types of files to provision infrastructure resources. Besides CloudFormation, work for supporting HashiCorp Terraform is currently underway.
Listing 1 shows an example of an environment template (cloudformation.yaml).
Listing 1
AWSTemplateFormatVersion: '2010-09-09'
Description: AWS Fargate cluster running containers in a public subnet. Only supports public facing load balancer, and public service discovery namespaces.
Parameters: # customization parameters
VpcCIDR: # customization parameter
Description: CIDR for VPC
Type: String
Default: "10.0.0.0/16"
SubnetOneCIDR: # customization parameter
Description: CIDR for SubnetOne
Type: String
Default: "10.0.0.0/24"
SubnetTwoCIDR: # customization parameters
Description: CIDR for SubnetTwo
Type: String
Default: "10.0.1.0/24"
Resources:
VPC:
Type: AWS::EC2::VPC
Properties:
EnableDnsSupport: true
EnableDnsHostnames: true
CidrBlock:
Ref: 'VpcCIDR'
# Two public subnets, where containers will have public IP addresses
PublicSubnetOne:
Type: AWS::EC2::Subnet
Properties:
AvailabilityZone:
Fn::Select:
- 0
- Fn::GetAZs: {Ref: 'AWS::Region'}
VpcId: !Ref 'VPC'
CidrBlock:
Ref: 'SubnetOneCIDR'
MapPublicIpOnLaunch: true
PublicSubnetTwo:
Type: AWS::EC2::Subnet
Properties:
AvailabilityZone:
Fn::Select:
- 1
- Fn::GetAZs: {Ref: 'AWS::Region'}
VpcId: !Ref 'VPC'
CidrBlock:
Ref: 'SubnetTwoCIDR'
MapPublicIpOnLaunch: true
# Setup networking resources for the public subnets. Containers
# in the public subnets have public IP addresses and the routing table
# sends network traffic via the internet gateway.
InternetGateway:
Type: AWS::EC2::InternetGateway
GatewayAttachement:
Type: AWS::EC2::VPCGatewayAttachment
Properties:
VpcId: !Ref 'VPC'
InternetGatewayId: !Ref 'InternetGateway'
PublicRouteTable:
Type: AWS::EC2::RouteTable
Properties:
VpcId: !Ref 'VPC'
PublicRoute:
Type: AWS::EC2::Route
DependsOn: GatewayAttachement
Properties:
RouteTableId: !Ref 'PublicRouteTable'
DestinationCidrBlock: '0.0.0.0/0'
GatewayId: !Ref 'InternetGateway'
PublicSubnetOneRouteTableAssociation:
Type: AWS::EC2::SubnetRouteTableAssociation
Properties:
SubnetId: !Ref PublicSubnetOne
RouteTableId: !Ref PublicRouteTable
PublicSubnetTwoRouteTableAssociation:
Type: AWS::EC2::SubnetRouteTableAssociation
Properties:
SubnetId: !Ref PublicSubnetTwo
RouteTableId: !Ref PublicRouteTable
# ECS Resources
ECSCluster:
Type: AWS::ECS::Cluster
# A security group for the containers we will run in Fargate.
# Rules are added to this security group based on what ingress you
# add for the cluster.
ContainerSecurityGroup:
Type: AWS::EC2::SecurityGroup
Properties:
GroupDescription: Access to the Fargate containers
VpcId: !Ref 'VPC'
# This is a role which is used by the ECS tasks themselves.
ECSTaskExecutionRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Statement:
- Effect: Allow
Principal:
Service: [ecs-tasks.amazonaws.com]
Action: ['sts:AssumeRole']
Path: /
ManagedPolicyArns:
- 'arn:aws:iam::aws:policy/service-role/AmazonECSTaskExecutionRolePolicy'
...

Develop state-of-the-art serverless applications?
Explore the Serverless Development Track
Using schema files for environments and services
When administrators use OpenAPI Data Models [1] to define a parameter schema file for a template bundle, AWS Proton can validate parameter value inputs against the requirements that have been defined in the schema. Your schema must follow the data models (Schemas) section of the OpenAPI in YAML format. It must also be a part of your environment schema bundle. Listing 2 defines an environment input type with a description and input properties (sample service schema file for an environment template).
Listing 2
schema: # required
format: # required
openapi: "3.0.0" # required
# required defined by administrator
environment_input_type: "PublicEnvironmentInput"
types: # required
# defined by administrator
PublicEnvironmentInput:
type: object
description: "Input properties for my environment"
properties:
vpc_cidr: # parameter
type: string
description: "This CIDR range for your VPC"
default: 10.0.0.0/16
pattern: ([0-9]{1,3}\.){3}[0-9]{1,3}($|/(16|24))
subnet_one_cidr: # parameter
type: string
description: "The CIDR range for subnet one"
default: 10.0.0.0/2
pattern: ([0-9]{1,3}\.){3}[0-9]{1,3}($|/(16|24))
subnet_two_cidr: # parameter
type: string
description: "The CIDR range for subnet two"
default: 10.0.1.0/24
pattern: ([0-9]{1,3}\.){3}[0-9]{1,3}($|/(16|24))
Listing 3 shows an example of a service schema file for a service that includes an AWS Proton service pipeline.
Listing 3
schema: # required
format: # required
openapi: "3.0.0" # required
# required defined by administrator
service_input_type: "LoadBalancedServiceInput"
# only include if including AWS Proton service pipeline, defined by # administrator
pipeline_input_type: "PipelineInputs"
types: # required
# defined by administrator
LoadBalancedServiceInput:
type: object
description: "Input properties for a loadbalanced Fargate service"
properties:
port: # parameter
type: number
description: "The port to route traffic to"
default: 80
minimum: 0
maximum: 65535
desired_count: # parameter
type: number
description: "The default number of Fargate tasks you want running"
default: 1
minimum: 1
task_size: # parameter
type: string
description: "The size of the task you want to run"
enum: ["x-small", "small", "medium", "large", "x-large"]
default: "x-small"
image: # parameter
type: string
description: "The name/url of the container image"
default: "public.ecr.aws/z9d2n7e1/nginx:1.19.5"
minLength: 1
maxLength: 200
unique_name: # parameter
type: string
description: "The unique name of your service identifier. This will be used to name your log group, task definition and ECS service"
minLength: 1
maxLength: 100
required:
- unique_name
# defined by administrator
PipelineInputs:
type: object
description: "Pipeline input properties"
properties:
dockerfile: # parameter
type: string
description: "The location of the Dockerfile to build"
default: "Dockerfile"
minLength: 1
maxLength: 100
unit_test_command: # parameter
type: string
description: "The command to run to unit test the application code"
default: "echo 'add your unit test command here'"
minLength: 1
maxLength: 200
After the environment, service infrastructure template files and the associated schema files have been prepared, they must be organized into directories. The directory structure of the service template bundles is defined as seen in Listing 4.
Listing 4
/schema
schema.yaml
/infrastructure
manifest.yaml
cloudformation.yaml
Additionally, a manifest file must be created. The manifest file lists the infrastructure files and has to adhere to the format and content as shown in Listing 5.
Listing 5
infrastructure:
templates:
- file: "cloudformation.yaml"
rendering_engine: jinja
template_language: cloudformation
After the directories and manifest files are set up for the environment or service template bundle, the directories must be compressed into a tar ball and uploaded to an Amazon S3 bucket where AWS Proton can retrieve them. AWS Proton checks templates for the correct file format, but it does not check for dependencies and logic errors. For example, let us assume that the creation of an Amazon S3 Bucket has been specified in an AWS CloudFormation template file as a part of the service or environment templates. A service is created based on these templates. Then, let’s assume that the service will be deleted at some point. When the specified S3 bucket is not empty and the CloudFormation template does not mark it as Retain in the DeletionPolicy, then AWS Proton fails to delete the service.
Under [2], you will find a repository containing a curated list of AWS Proton templates. Currently, there are three different templates.
- AWS Proton Sample Load-Balanced Web Service and microservices are each based on Amazon ECS and AWS Fargate: This directory contains sample templates for AWS Proton environments and services for an Amazon ECS Service with Load Balancing running on AWS Fargate, as well as sample specifications for creating Proton environments and services using templates. The environment template contains an ECS cluster and a VPC with two public subnets. The service templates contain all of the resources required to create an ECS Fargate service behind a load balancer in this environment, as well as sample specifications for creating Proton environments and services using the templates.
- AWS Proton Sample Multi-Service: This directory contains sample templates that show how AWS Proton environments can be used to create shared resources for multiple services. The environment template contains a simple Amazon DynamoDB table and an S3 Bucket. A service template creates a simple CRUD API service supported by AWS Lambda functions and an API Gateway, and includes an AWS CodePipeline for Continuous Delivery. The second service template creates a data processing service that consumes data from an API, pushes that data into a Kinesis Stream. It is then consumed by another Lambda function and pushes the data into a firehose, which ends up in the S3 Bucket configured by the environment template.
AWS Proton has been generally available since June 2021 and like other container services, it has a public roadmap [3]. In the roadmap, you can see which functionalities were released recently, what will be released soon, what the service team is currently working on, and what is currently being researched. For example, the service team is currently working on supporting HashiCorp Terraform [4] so that the infrastructure can also be built by Terraform scripts.
Learn more about Serverless Architecture ConferenceSTAY TUNED!
Conclusion
AWS Proton is a new service for deploying container-based and serverless applications that implements a popular set-up used by large companies, where administrators build a shared service platform that developers can use to roll out their applications. Administrators define templates that developers can use as a basis. These templates provide a high degree of flexibility in order to define the desired infrastructure.




