The cloud is changing the way software solutions are developed, designed, and operated. The focus is on the development of small and independent services. Communication between the services takes place via defined interfaces. These can be both synchronous (e.g. request/response) and asynchronous (e.g. events or commands). Depending on the workload, they can be scaled individually. For cloud applications to function properly despite distributed states, stability and resilience should be considered during planning. Additionally, monitoring telemetry data is important in order to gain insight into the system in case anomalies occur in the application process.
Learn more about Serverless Architecture ConferenceSTAY TUNED!
First considerations
Before you can begin developing cloud solutions, you should discuss and design the basic architecture of the application. In the following sections, we will look at the most popular architectural styles and explain their advantages and disadvantages.
N-tier architecture
Perhaps the best-known style is N-tier architecture. When developing monolithic applications, this principle is used in most cases. When designing the solution, logical functions are divided into layers, as seen in Figure 1. The conventional layers (presentation layer/UI, business layer, data layer) build on each other, which means that communication only takes place from a higher-level layer to a lower-level layer. For example, the business layer does not know any details of the UI. Communication between these layers always starts from the UI.
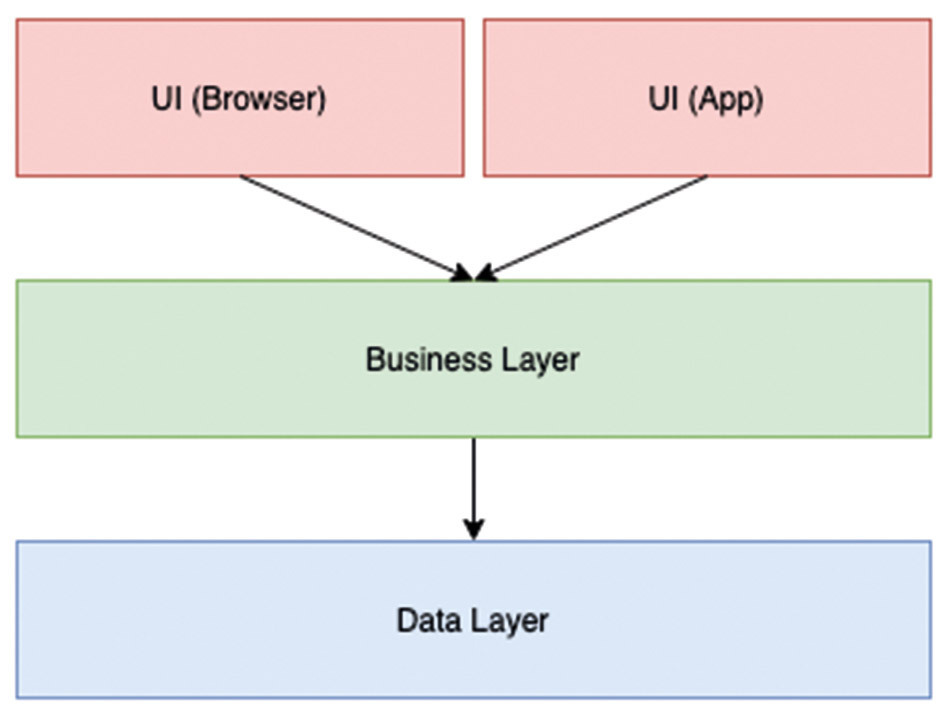
In the context of cloud development, layers can be hosted on their own instances and communicate with each other via interfaces. As a rule, N-tier architectures are used when the application is implemented as an Infrastructure-as-a-Service (IaaS) solution. In this case, each layer is hosted on its own virtual machine. In the cloud, it makes sense to use additional managed services, such as a content delivery network, load balancer, caching, or design patterns like the Circuit Breaker.
The N-tier architecture’s strengths lie in its ease of execution on local systems and in the cloud. It also lends itself to the development of simple web applications. As soon as the business functions of an application become more complex or the scaling of individual business functions is in the foreground, architectures are offered. In contrast, these are not monolithic. With these principles, individual business requirements can be hosted and scaled separately.
Microservices architecture
As already touched upon, this method is useful when the complexity of an application increases because individual domains (business functions) can be developed separately [2]. Each microservice can be created individually and only needs to implement coordinated interfaces (Fig. 2). For example, Microservice 1 can be developed with .NET and Microservice 2 with Node.js. The technologies used should be selected in order to easily meet business requirements. Scaling can be performed individually for each microservice since the microservices are loosely coupled. Therefore, the process does not have to be applied to the entire application if only individual domains have high traffic. Significantly smaller code bases are easier to check automatically with unit tests and can be refactored more easily afterward, increasing code quality.
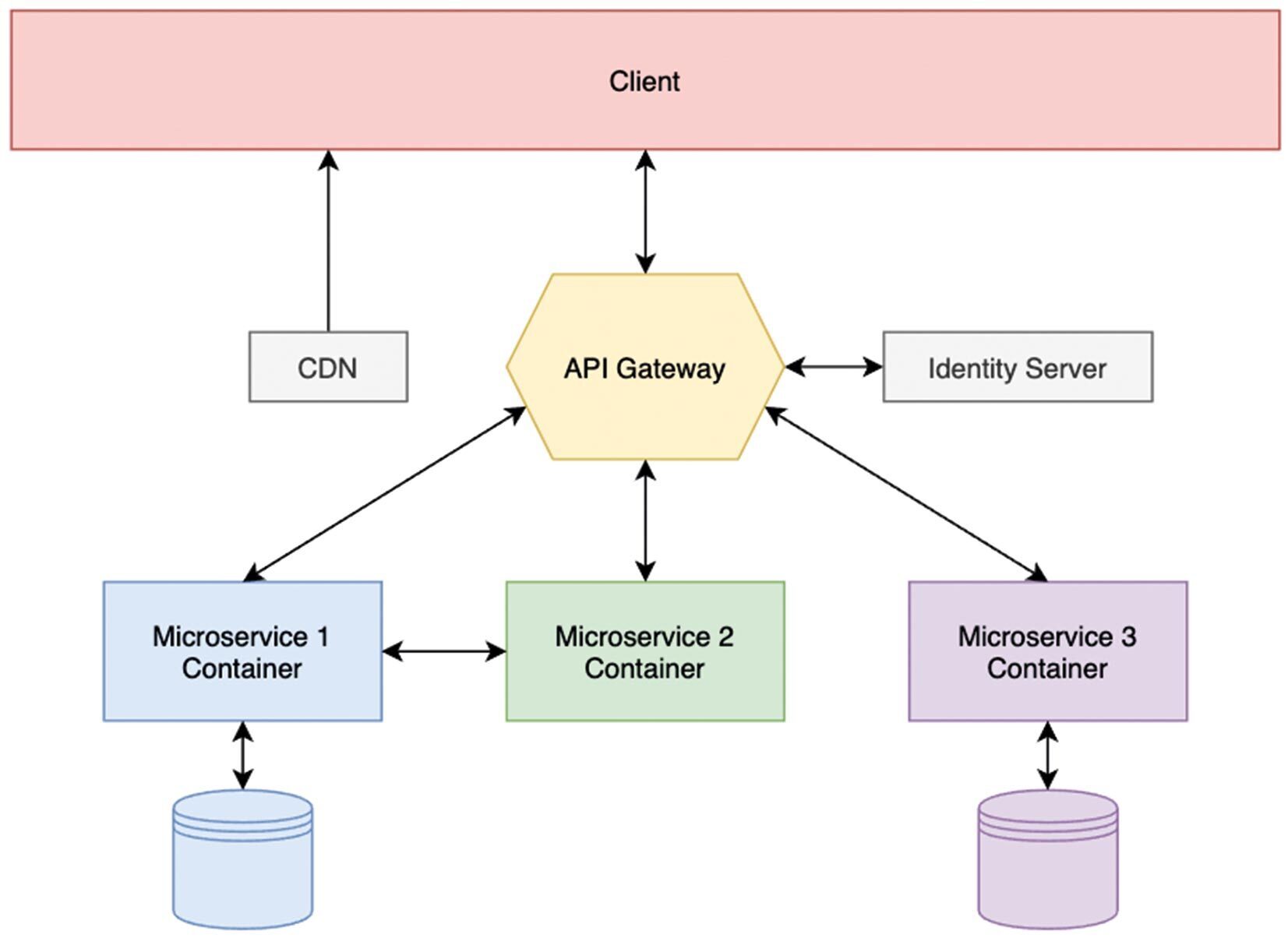
The biggest disadvantage of a microservices architecture is ensuring communication between individual services.
Event-driven architecture/serverless computing
An event-driven architecture uses events to communicate between decoupled services. These procedures have three key components regarding events: Producers, Routers, and Consumers. A producer publishes events to the router, which filters and forwards them to consumers. Producer and consumer services are decoupled, allowing them to scale, update, and deploy independently. This principle can also be integrated into a microservices architecture or a monolith, making the architectural models complementary.
An event-driven architecture can be built on a pub/sub model or an event notification model. The former is a messaging infrastructure where event streams are subscribed to. When an event occurs or is published, it is sent to the respective subscribers/consumers (Fig. 3).
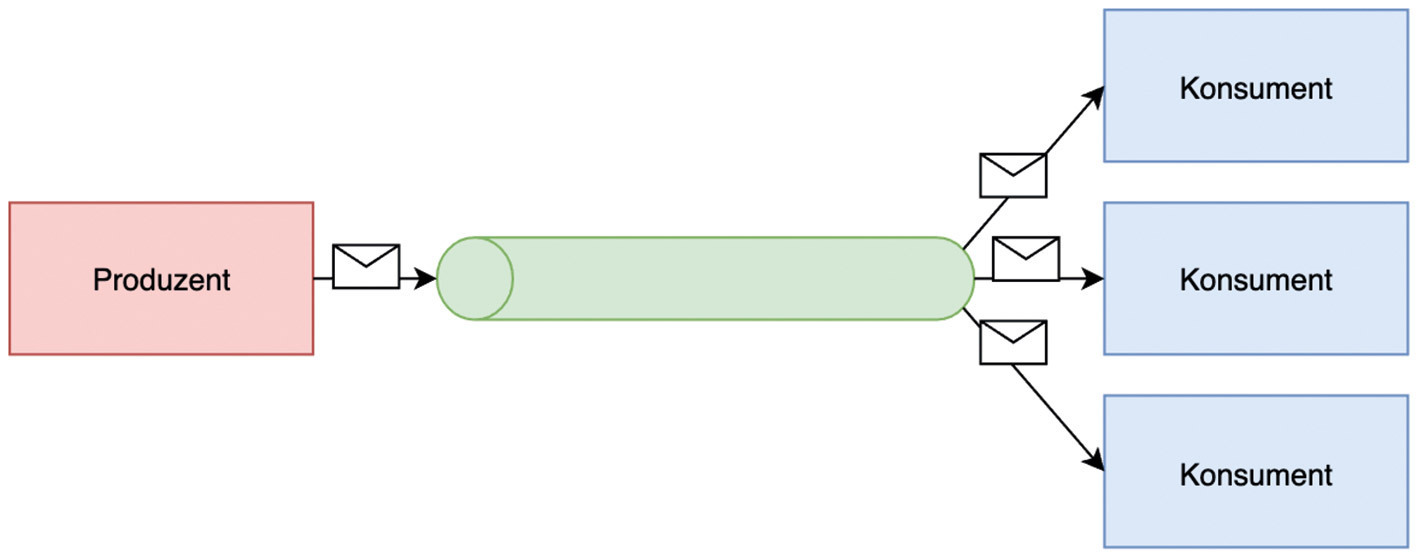
In the event notification model, events are written to a queue, processed by the first event handler, and removed from the queue. This behavior is beneficial when events may only be processed once. If an error occurs during processing, then the event is written back to the queue. In the simplest variant, an event triggers an action directly in the consumer. This can be an Azure Function that implements a queue trigger, for example. One advantage of using this microservice and the related Azure Storage Queue is that both services are serverless.
This means that these services only run when they are needed. It’s more cost-effective than being continuously available, which can incur high costs. Serverless is also a good choice when you require rapid provisioning and the application scales automatically depending on the workload. Since serverless services are provided by the cloud operator, one drawback is a strong commitment to the operator.

Design principles
The following sections explain design principles that help optimize applications in terms of scalability, resilience, and maintainability. Particular attention is paid to cloud application development.
Self-healing applications
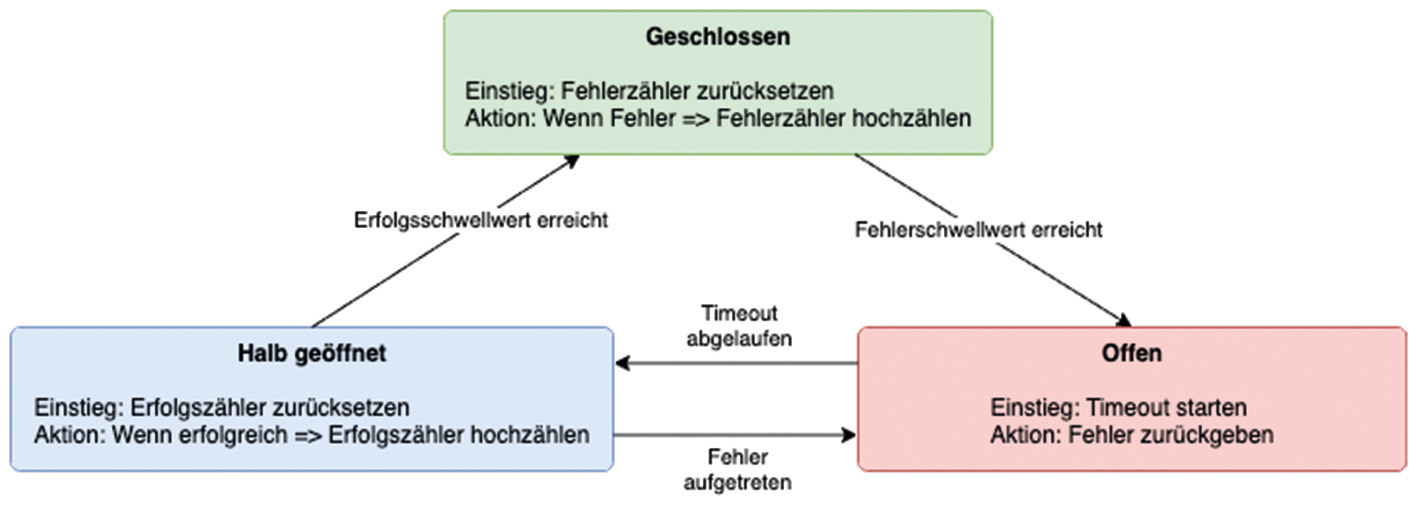
In distributed systems, hardware can occasionally fail, network errors can occur, or remote systems can become unavailable. In these cases, it is useful if applications know what to do and remain operable for the user. When a remote system is not available, it isn’t clear at first whether it’s a short-term or longer-term failure. In this case, the circuit breaker pattern provides a remedy. Depending on the configuration, this pattern is used together with the Retry pattern. Most of the time, these are only minor faults that only last for a short time. In these cases, it is sufficient for the application to repeat the failed call after a certain period of time with the help of the retry pattern. Then, if an error occurs again and the remote system fails for a longer period, the circuit breaker pattern is used. Figure 4 shows the structure of this pattern. A circuit breaker acts as a proxy for operations that may experience errors. The proxy will monitor the number of recent errors and decide whether to continue the operation or immediately return an exception. When closed, requests are forwarded to the remote system. If an error occurs during this process, then the error counter’s number goes up. Once the error threshold is exceeded, the proxy is set to the “open” state.
In this state, requests are answered directly with an error and an exception is returned. Once a timeout has expired, the proxy is in the “half-open” state. A limited number of requests are allowed. If these are successful, the proxy transitions to the closed state and allows requests again. However, if another failure occurs, it switches back to “open”. The semi-open state prevents sensitive systems from being flooded with requests after they become available again.
.NET developers are recommended to take a closer look at Polly [1]. This is a .NET resilience and transient fault handling library that allows developers to express policies such as retry, circuit breaker, timeout, bulkhead, isolation, and fallback in a thread-safe manner.
Minimize coordination
For applications to scale, individual services of an application (frontend, backend, database, or similar) must be executed on their own instances. It becomes an issue when two instances want to execute an operation simultaneously that affects a common state. One of the two instances is locked until the other instance is finished with the operation. The more instances are available, the bigger communication issues become. As a result, the advantage of scaling becomes smaller and smaller. Event sourcing is an architectural pattern that locks operations only for a short time. Here, all changes are mapped and recorded as a series of events. Unlike in classic relational databases, the current state of the application is not stored, but instead the individual changes that led to the current state over time. The decisive factor is that only new entries may be added. These events are stored in the Event Store. Above all, it must support fast insertion of events and serves as a single source of truth.
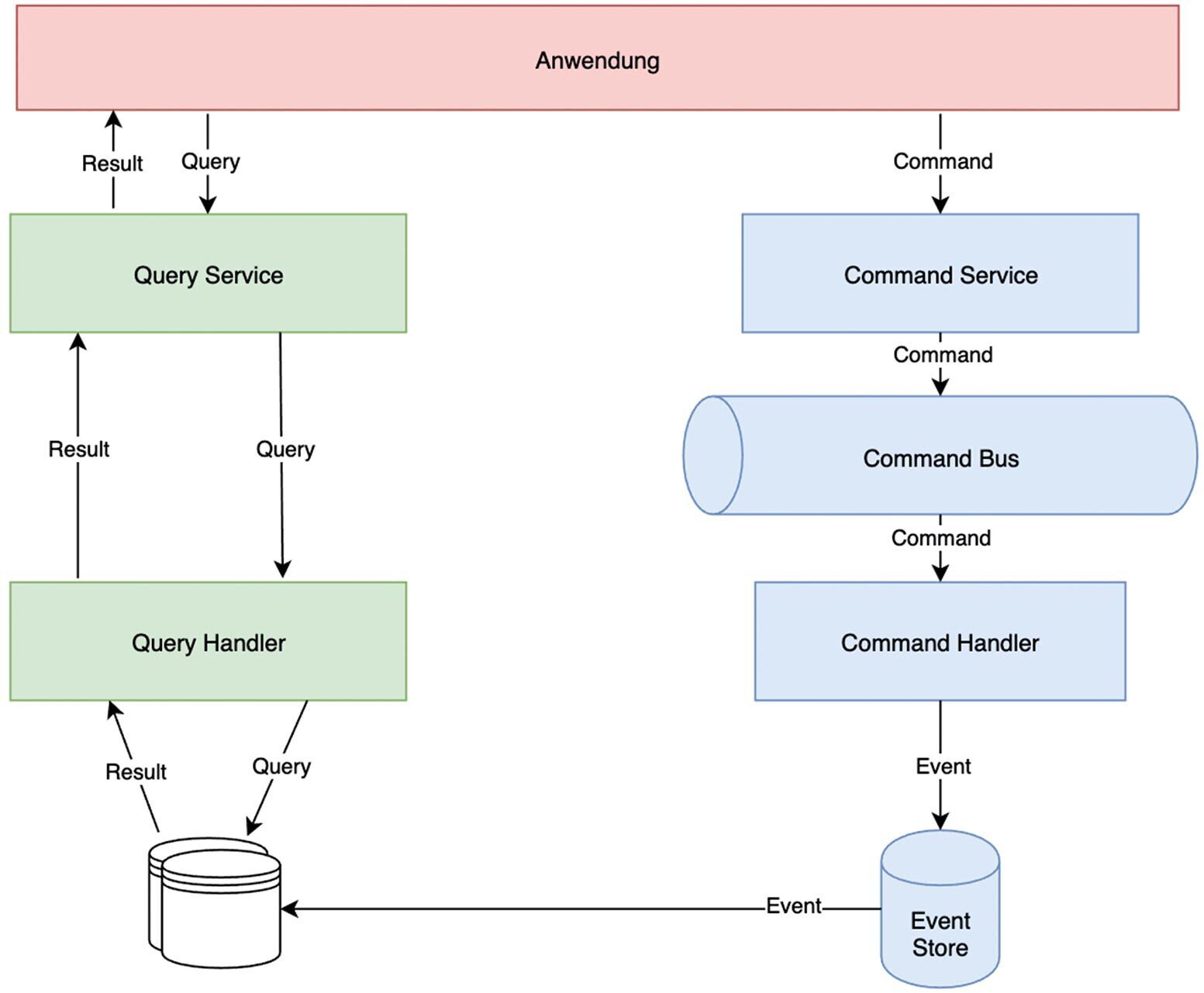
Another architecture pattern is CQRS (Command Query Responsibility Segregation). Here, the application is separated into two parts: a read service and a write service. The advantages are the different scalability and adaptability to business requirements. CQRS excels when combined with event sourcing. For example, you can use event sourcing in the write service and implement an optimized query for event sourcing entries in the read service. Figure 5 shows that in a simple case, a command is added to a queue and processed as soon as a command handler is available. Events in the event store are transferred to the databases according to their changes. Systems developed with this model do not offer any consistency guarantees (eventual consistency) in the standard. For performance reasons, in the eventual consistency model, data is not immediately distributed to all servers or partitions during write operations. Instead, algorithms are used to ensure that the data is consistent after the write operations have been completed. As a rule, no statements are made about the operation’s time period.
Alignment with business requirements
The design patterns you use must support business requirements. It is important to know whether a thousand or millions of users a day will use the application. Likewise, you must know how fail-safe the application must be. The first step should be defining the non-functional requirements. Design patterns can be analyzed and checked for non-functional requirements. If the software is complex, Domain-Driven Design (DDD) can be an option for software modeling. In short, DDD focuses on the domain-oriented nature of the software and the business logic, which is the basis for both the architecture and the implementation. This is a logical step, considering that software supports business processes. The microservices’ architecture is often used in conjunction with domain-driven design, where each functionality (bounded context) is mapped as a microservice. As per the principle “Do one thing and do it well”, each bounded context has exactly one functional task. From a technical point of view, one service is implemented for each bounded context, which is responsible for data management, business logic, and the user interface. Additionally, Onion Architecture has become established in DDD. Figure 6 shows the structure of this principle.
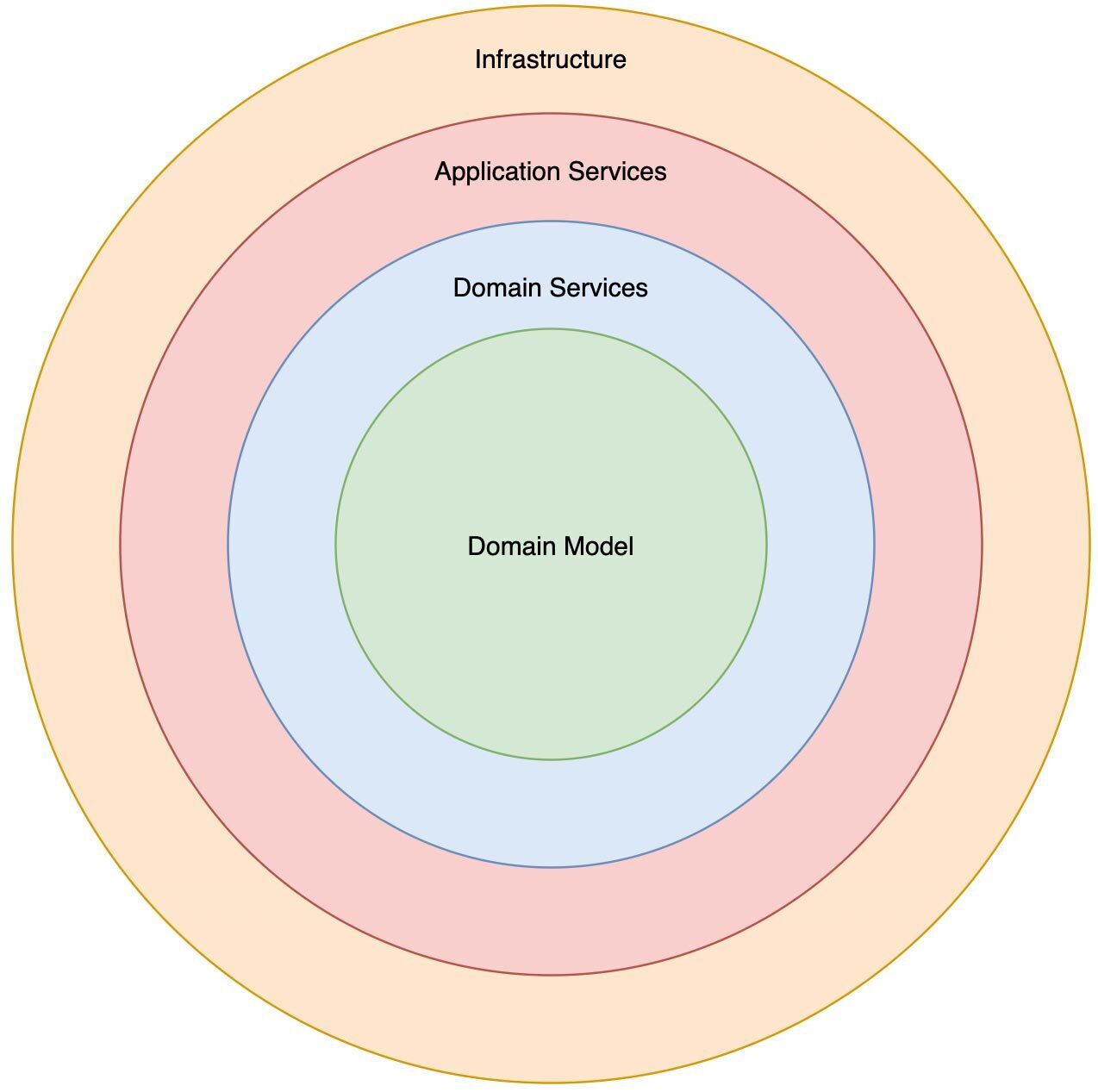
In contrast to other architectures, the Onion Principle places professionalism at the center. Only the outer layers may access the inner layers. As a result, domain-oriented code is separated from application code. Long-lasting business logic remains untouched when changes are necessary at the infrastructure level. By separating infrastructure aspects and business logic in the Onion Architecture, the domain model is largely free of the technical aspects mentioned above. In addition to the simpler testability of business logic, this allows for more readable business code.
Learn more about Serverless Architecture ConferenceSTAY TUNED!
Conclusion
In order to exploit the full potential of the cloud, all non-functional requirements should be defined before an application is developed. This prior knowledge will help you find the right design patterns, basic architectures, and combine them. Especially in the case of distributed systems, software developers, software architects, and domain experts should give more thought to behavior in the event of an error.
Links & Literature
[1] http://www.thepollyproject.org
[2] https://medium.com/brickmakers/cloud-architekturen-im-%C3%BCberblick-d7b6a366fc5d




