In the previous article about SaaS operations at the customer site, we looked at Amazon ECS Anywhere, a platform that allows external hardware to be added to a control plane fully managed in the Cloud. We saw that software vendors and their customers can greatly reduce operational overhead in on-premises deployment using ECS Anywhere and can standardize their delivery and operational concepts across environments. If a team is considering deploying an application with containers, ECS isn’t the only option. Kubernetes is likely to be included in the shortlist of platforms in most cases. 88% of all companies from a recent Red Hat study [1] state they are using Kubernetes – 74% of which in production. This wide adoption in the industry motivated the fast development of a huge ecosystem around Kubernetes. The Cloud Native Computing Foundation (CNCF) Landscape lists over a thousand projects, products, and partners [2]. This provides SaaS providers with a big benefit: many building blocks needed in SaaS are available for integration and don’t need to be build by themselves.
Another advantage is the cross-environment standardization of application deployment and operations. If SaaS providers develop their product for Kubernetes as a runtime environment, the platform serves as an abstraction layer and reduces development and support efforts in hybrid scenarios – after all, the basic deployment and operation concepts do not differ between the SaaS and the external customer environment. In this article, we therefore look at how an on-premises Kubernetes environment can look like that promotes the portability of an application.
Learn more about Serverless Architecture ConferenceSTAY TUNED!
Kubernetes Overview
A Kubernetes cluster can be roughly divided into two parts. The control plane contains software components for operating the cluster. This includes the Kubernetes API for externally changing the cluster state (for example, by administrators), controllers for processing events in the cluster (for example, scaling), and a key-value store for managing state in the cluster (etcd). High availability, seamless maintenance without interuptions and auto-scaling of the control plane is mandatory for productive SaaS offerings in Kubernetes.
The second part of a Kubernetes cluster is the data plane. This is where the scheduler places the actual workload. In addition to a container runtime like containerd, kubelet is an agent for communicating with the control plane. Kube-proxy is a proxy for network traffic on all nodes in the data plane (Fig. 1).

Fig. 1: Overview of a Kubernetes cluster’s components
Even though Kubernetes can simplify SaaS solutions’ operations, the platform is complex and calls for a high level of expertise. Dedicated platform teams are usually tasked with running the Kubernetes cluster. Similar to operational expenses for edge systems (such as databases or storage clusters), software vendors should consider managed Kubernetes services from the Cloud provider to help reduce the total cost of ownership.
Amazon EKS – Kubernetes as a Service
Amazon Web Services (AWS) offers Amazon Elastic Kubernetes Service (EKS), a CNCF-certified Kubernetes distribution as a managed service. This certification means that EKS follows defined standards and compatibility checks are executed continously. This means that an application running in EKS can also be executed in other CNCF-certified
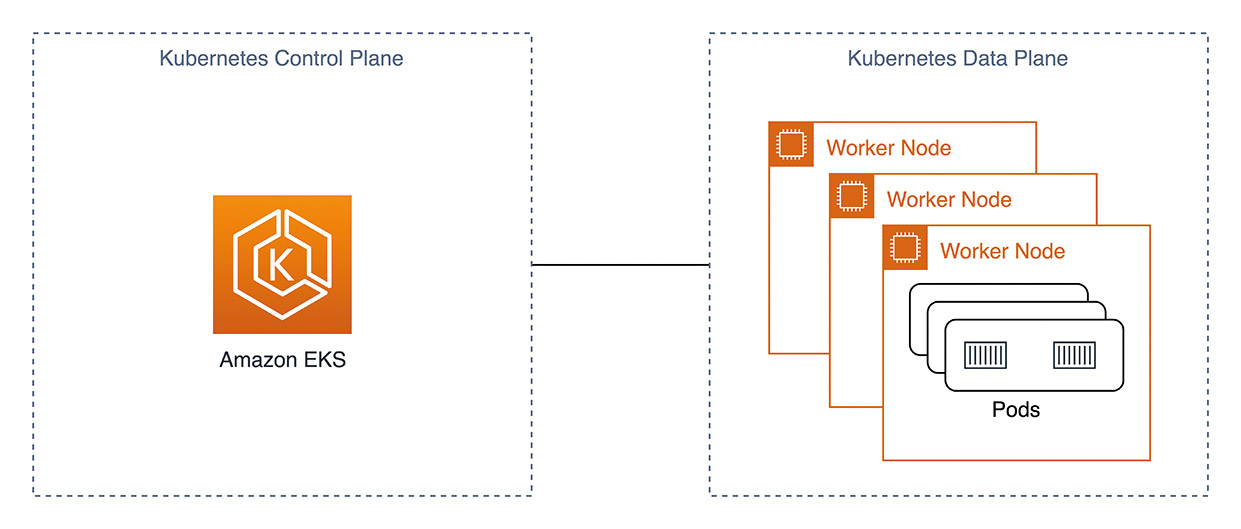
Fig. 2: Amazon EKS high-level architecture
EKS provides the Kubernetes Control Plane as a managed service. Users are no longer responsible for the majority of components in Figure 1, and the cluster architecture is simplified, as seen in Figure 2. Operational tasks around the Data Plane can also be reduced with Managed Node Groups [3] and AWS Fargate [4].
AWS works very closely with the open source community and is an active maintainer of Kubernetes plug-ins and contributes to the core product. More information about the commitment of AWS to the open source community around Kubernetes and containers can be found in the public roadmap on GitHub [5].
Runs in Kubernetes = runs everywhere?
When people talk about the advantages of Kubernetes, the word “portability” quickly comes up. Software vendors who want to offer their products in different environments are looking for exactly that: a deployment model that is as portable as possible. Unfortunately, a closer look shows that even with Kubernetes, complex products can only achieve portability to a limited extent [6].
Processes, concepts, and capabilities in your team make Kubernetes naturally portable with an abstraction from the infrastructure provider’s underlying hardware and APIs. However, applications are selfcontained and work without external dependencies only in the simplest cases.
For example, many SaaS solutions integrate managed services from the Cloud. For basic services like relational databases or message queues, self-managed alternatives can be deployed in Kubernetes or the on-premises infrastructure. But for other, often higher-value services (like AI/ML services or highly specialized databases), you need alternatives. That leads to differences between on-premises and Cloud deployments.
But the Kubernetes platform can also become a building block, allowing the two deployment models to diverge. Kubernetes is evolving rapidly and functionalities are already being used productively in beta or even alpha status. Deployment for a current platform version as a managed service in the Cloud may fail on-premises since functions used in templates aren’t available. Furthermore, Kubernetes is very flexible and allows operations teams to extend and change the platform’s functionality and behavior with plug-ins or WebHooks. The large number of available plug-ins increases the complexity of quality assurance for software products. This is comparable to the effort of testing a native app for the highly fragmented market of Android devices.
Therefore, software vendors should use standardized Kubernetes distributions to at least reduce complexity related to the platform itself. One distribution that’s interesting for SaaS providers with an AWS-based solution is the free, CNCF-certified open source distribution Amazon EKS Distro (EKS-D) [7]. It’s a distribution of Kubernetes and other core components used by AWS to deploy EKS in the Cloud. This includes binaries and containers from the open source Kubernetes project, etcd, networking, and storage plug-ins. All components are continuously tested for compatibility. EKS-D also provides extended support for Kubernetes releases after community support expired by updating releases of previous versions with the latest critical security patches.
Amazon EKS Anywhere
Amazon EKS Anywhere, released in September 2021, is a new option for running Kubernetes clusters on your own infrastructure. It’s a bundle consisting of EKS-D and a number of third-party open source components commonly used with Kubernetes. By using EKS Anywhere, teams reduce the overhead associated with on-premises Kubernetes operations. All components included in the bundle are updated by AWS and compatibility is validated. EKS Anywhere enables the consistent generation of clusters. Additionally, SaaS providers can keep their tooling homogeneous across Cloud and on-premises deployments.
Unlike Amazon ECS Anywhere discussed in the first article of this series, the data plane and the control plane of EKS Anywhere are both located outside the Cloud. The deployment options for EKS and EKS Anywhere are shown in Figure 3.

Fig. 3: Deployment options for Amazon EKS and Amazon EKS Anywhere
When using Amazon EKS and a fully AWS-managed control plane in the Cloud, nodes for the data plane can be composed of any of the following runtime environments:
- Self-Managed Node Groups: EC2 instances fully managed by the customer.
- Managed Node Groups: EC2 instances that AWS provides lifecycle management and EKS-optimized base images for.
- Amazon Fargate: The serverless compute option for containers, where AWS fully manages the underlying infrastructure.
- Amazon Outposts: AWS-provided infrastructure with a set of AWS Cloud Services for on-premises deployments.
The options for Amazon EKS Anywhere are more homogenous. Control and data plane need to be deployed to either VMs in a VMware vSphere cluster or bare metal machines in a cluster managed by the bare metal provisioning engine Tinkerbell [8]. AWS provides base images for nodes in the EKS Anywhere cluster independent of the choice of the infrastructure provisioner. Customers can choose between Ubuntu or Bottlerocket — an open source operating system optimized for container operation [9]. As you’ll see below, EKS Anywhere uses the Kubernetes project Cluster API [10], which introduces Kubernetes Custom Resource Definitions (CRDs) for infrastructure components like nodes. Therefore, cluster lifecycle management can be performed by Kubernetes itself. Cluster API acts as a proxy to the specific infrastructure provider.
When it comes to components included in the EKS Anywhere bundle, the open source Kubernetes distribution EKS-D is central. As previously mentioned, this is a compilation of Kubernetes and some dependencies used by AWS for deploying Amazon EKS in the Cloud. Additionally, EKS Anywhere includes lifecycle management tools for the cluster. It includes eksctl – developed by Weaveworks and AWS – to create, scale, upgrade, and tear down clusters. For GitOps workflows, EKS Anywhere includes Flux v2 – also from Weaveworks. For cluster access management, aws-iam-authenticator – for integration with AWS IAM – and OpenID Connect (OIDC) support are available. EKS Anywhere also bundles together the Node operating system images (Ubuntu, Bottlerocket) and the container network interface (CNI) plug-in Cilium. Of course, EKS Anywhere offers the usual flexibility with extensions and integrations for components that aren’t currently available in the bundle. Later, we’ll see an example of this and enable load balancing with MetalLB.
Cluster management with Cluster API
A central component in EKS Anywhere is the Project Cluster API (CAPI). It provides declarative Kubernetes APIs for provisioning, upgrading, and operating Kubernetes clusters. It simplifies tasks around cluster provisioning and helps standardize them across infrastructure providers. Today, EKS Anywhere supports Docker for development and test systems as well as vSphere and BareMetal for production environments.
You need access to the infrastructure provider’s API and a dedicated administration server to get started. On this server, eksctl is used to generate the cluster configuration and execute the provisioning process. Before the actual workload cluster is created in the infrastructure provider’s environment, eksctl creates a local bootstrap cluster with kind [11] on the administrator server.
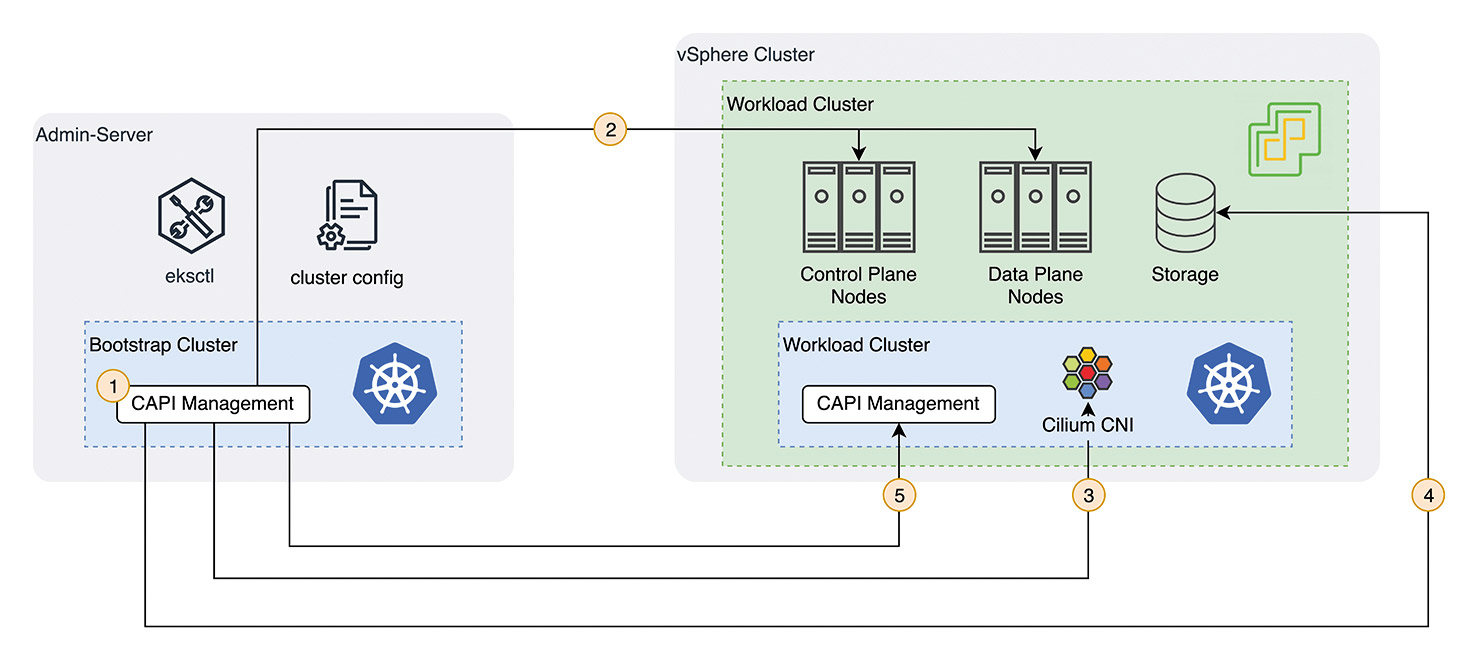
Fig. 4: Provisioning process of an EKS Anywhere cluster on VMware vSphere
Figure 4 shows the provisioning process for the VMware vSphere provider in detail. In this bootstrap cluster, the CAPI objects are initially created (1 in Fig. 4). CAPI objects are Custom Resource Definitions (CRDs). For example: Machine as a representation of a node in the cluster, or BoostrapData as a representation of the cloud-init scripts for newly added nodes. Nodes for control and data plane described via CRDs are then created in the vSphere cluster (2).
Once the workload cluster is successfully started, the bootstrap cluster begins configuration. The Cilium CNI is installed for networking in the workload cluster (3) and storage for persistent volumes is created in the vSphere cluster (4). Since we only need the bootstrap cluster temporarily to create the workload cluster, the CAPI objects are finally transferred to the workload cluster (5). For future maintenance of the cluster, the temporary bootstrap cluster is restarted and CAPI objects are synchronized with the workload.
The provisioning process for BareMetal is also based on Cluster API and works similar. The main difference with this infrastructure provider is the provisioning of cluster nodes. It uses the Tinkerbell engine and its component to install base images using preboot execution environment (PXE) on physical machines on the same (Layer 2) network. Please refer to the official documentation of Tinkerbell [7] and EKS Anywhere’s BareMetal provisioner [12] to get started with this deployment option.
EKS Anywhere in Action
The first step on our way to an EKS Anywhere cluster is setting up an administration server. For this, we need a physical or virtual machine meeting the following requirments:
- 4 CPU cores, 16 GB RAM and 30 GB free hard disk space,
- Mac OS (from version 10.15) or Ubuntu (from version 20.04.2 LTS) for the operating system, and
- Docker (from version 20.0.0).
The tools eksctl and eksctl-anywhere need to be installed on that server. One option is to use homebrew:
brew install aws/tap/eks-anywhere
Additional installation options can be found in EKS Anywhere’s official documentation [13].
EKS Anywhere currently supports three providers for cluster generation: vSphere, BareMetal and Docker. The Docker provider is intended for development and testing and doesn’t need any special hardware or licences. Therefore, in the following example we’ll use the Docker provider. First, create a cluster configuration with the following commands:
export CLUSTER_NAME=hello-eks-anywhere eksctl anywhere generate clusterconfig $CLUSTER_NAME \ --provider docker > $CLUSTER_NAME.yaml
This template already contains all of the information you need to create an EKS Anywhere cluster. Based on this, you can adapt the cluster to your own needs. For example, the CIDR ranges can be adapted to the given network, control and data plane can be scaled horizontally, OIDC providers can be integrated for access management, or GitOps can be activated for the cluster [14]. We will continue working here with the generated template (Listing 1) without making any changes.
Listing 1
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: Cluster
metadata:
name: hello-eks-anywhere
spec:
clusterNetwork:
cniConfig:
cilium: {}
pods:
cidrBlocks:
- 192.168.0.0/16
services:
cidrBlocks:
- 10.96.0.0/12
controlPlaneConfiguration:
count: 1
datacenterRef:
kind: DockerDatacenterConfig
name: hello-eks-anywhere
externalEtcdConfiguration:
count: 1
kubernetesVersion: "1.23"
managementCluster:
name: hello-eks-anywhere
workerNodeGroupConfigurations:
- count: 1
name: md-0
---
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: DockerDatacenterConfig
metadata:
name: hello-eks-anywhere
spec: {}
---
Create the EKS Anywhere cluster with this command:
eksctl anywhere create cluster -f $CLUSTER_NAME.yaml
Now, provider-specific conditions are validated before the local bootstrap cluster is started. If this was successful, the process from Figure 4 is executed. The eksctl tool writes a summary of individual steps to the command line output. Finally, eksctl writes a kubeconfig to the working directory. We can use this to access the newly created EKS Anywhere cluster (Listing 2).
Listing 2
cd $CLUSTER_NAME
export KUBECONFIG=${PWD}/${CLUSTER_NAME}-eks-a-cluster.kubeconfig
kubectl get ns
NAME STATUS AGE
capd-system Active 6m38s
capi-kubeadm-bootstrap-system Active 6m56s
capi-kubeadm-control-plane-system Active 6m43s
capi-system Active 7m
capi-webhook-system Active 7m2s
cert-manager Active 7m39s
default Active 8m32s
eksa-system Active 6m13s
etcdadm-bootstrap-provider-system Active 6m53s
etcdadm-controller-system Active 6m51s
kube-node-lease Active 8m34s
kube-public Active 8m34s
kube-system Active 8m34s
Now, we can place workloads in our EKS Anywhere cluster. For example, we can use kubectl to deploy a demo application:
kubectl apply -f "https://anywhere.eks.amazonaws.com/manifests/hello-eks-a.yaml"
After deploying the EKS Anywhere demo application, a pod runs in the default namespace:
kubectl get pods NAME READY STATUS RESTARTS AGE hello-eks-a-9644dd8dc-4l2z9 1/1 Running 0 13s
Networking and Load Balancing
In the demo application’s manifest, a service with the type NodePort was also created for the pod (Listing 3).
Listing 3
---
apiVersion: v1
kind: Service
metadata:
name: hello-eks-a
spec:
type: NodePort
selector:
app: hello-eks-a
ports:
- port: 80

With services of type NodePort, a port is reserved on all nodes in the cluster. This makes it possible to address the service from outside the cluster via the IPs of the nodes in the cluster. To invoke the demo application, we’ll proceed as in Listing 4.
Listing 4
kubectl get nodes
NAME STATUS ROLES AGE VERSION
hello-eks-anywhere-76htj Ready control-plane,master 12m v1.21.2-eks-1-21
hello-eks-anywhere-md-0-56f4f4cccd-hc6ff Ready <none> 15m v1.21.2-eks-1-21
kubectl describe node hello-eks-anywhere-md-0-56f4f4cccd-hc6ff | grep InternalIP
InternalIP: 172.18.0.6
kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
hello-eks-a NodePort 10.106.41.211 <none> 80:32626/TCP 12m
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 17m
curl http://172.18.0.6:32626
-----------------------------------------------------------------------------------------
Thank you for using
EKS ANYWHERE
You have successfully deployed the hello-eks-a pod hello-eks-a-9644dd8dc-4l2z9
For more information check out
https://anywhere.eks.amazonaws.com
-----------------------------------------------------------------------------------------
This information can now be used to statically configure external load balancers and route traffic using NodePorts to pods in EKS Anywhere. With Kubernetes in the Cloud, you’re more likely to use LoadBalancer type services to automate the process.
Services of the LoadBalancer type are assigned an IP address independent of the cluster nodes. It can be reached externally. A Cloud Controller Manager (CCM) in the Kubernetes Control Plane is responsible for the allocation. The component monitors Kubernetes objects of type Service and executes vendor-specific steps to provision an IP in the Cloud environment. Additionally, other controllers can respond to assigning an external IP and configure external load balancers to make the service reachable over the Internet. In Amazon EKS, for instance, native load balancers fully managed by AWS are deployed with the Elastic Load Balancer Service.
This managed service isn’t available outside the Cloud. EKS Anywhere supports MetalLB [15] because of this. It enables LoadBalancer type services on-premises by dynamically propagating routes to services running in Kubernetes to the local network outside of the cluster.
MetalLB consists of two components: a controller deployed as a ReplicaSet that assures that a single pod is running all the time and speaker pods deployed as DaemonSets to make sure one pods runs on each node in the cluster. While the operator monitors service creation and IP allocation, speakers are responsible to propagate service IPs on the local network and route traffic to a pod backing the requested service. MetalLB uses the Address Resolution Protocol (ARP) for IPv4 or Neighbor Discovery Protocol (NDP) for IPv6 to announce nodes responsible for service IP addresses. While this works without special hardware, it means, that services are only accessible for nodes on the same layer 2 network (resolving IP to MAC addresses). MetalLB supports Border Gateway Protocol (BGP) alternatively. This allows service IPs to be propagated in wider and more complex networks, given BGP compatible network infrastructure such as routers with route propagation is deployed. Figure 5 shows this workflow.
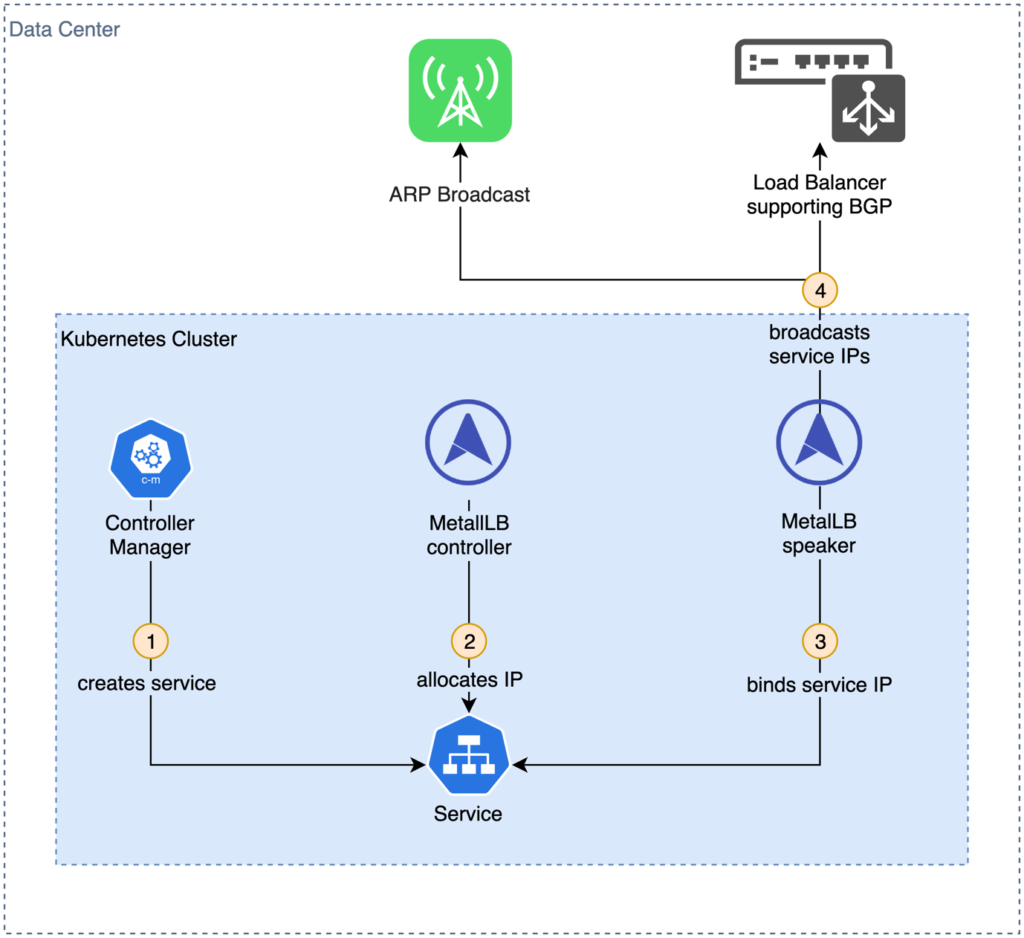
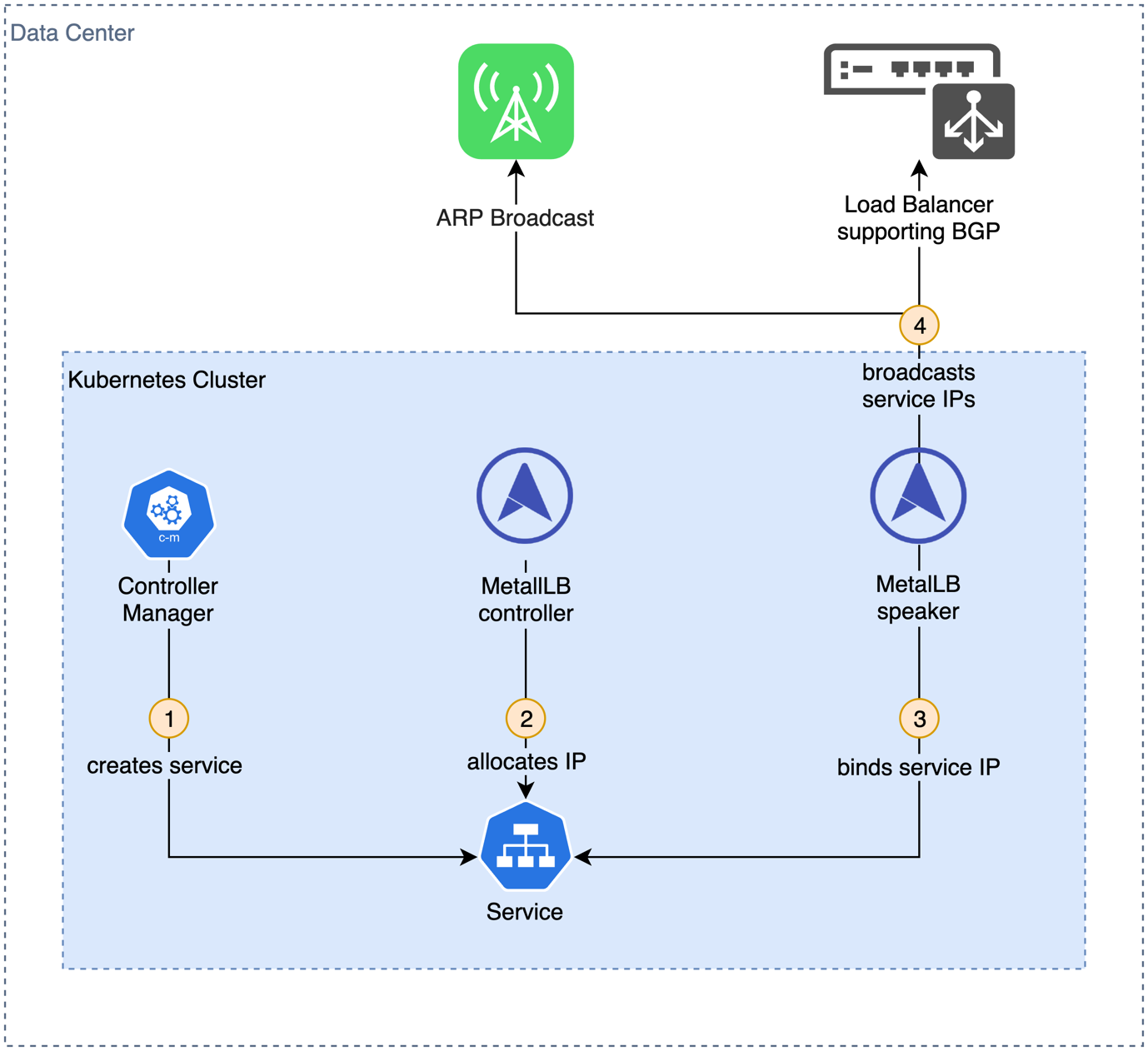
Fig. 5: Creating a load balancer service with kube-vip
MetalLB can be deployed in an EKS Anywhere cluster by installing a Helm chart: helm upgrade --install --wait --timeout 15m --namespace metallb-system --create-namespace --repo https://metallb.github.io/metallb metallb metallb
For IP allocation to work, MetalLB needs to be configured to use a routable and available CIDR range for service IPs. We can leverage the Docker provided IP range for the cluster’s bridge interface in our example:
docker network inspect -f '{{.IPAM.Config}}' kind
[{172.18.0.0/16 172.18.0.1 map[]} {fc00:f853:ccd:e793::/64 map[]}]
Any range from the 172.18.0.0/16 IP block can be used. So let us tell MetalLB to reserve 256 IPs from 172.18.200.0/24 by creating the following configuration file:
Listing 5
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: first-pool
namespace: metallb-system
spec:
addresses:
- 172.18.200.0-172.18.200.255
---
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:
name: example
namespace: metallb-system
The config file can be applied like any other Kubernetes template and will be picked up by the MetalLB controller pod:
Kubectl apply -f metallb-config.yaml
We can now create a service of type LoadBalancer for our demo application:
kubectl expose deployment hello-eks-a --port=80 \ --type=LoadBalancer --name=hello-eks-a-lb
This new service gets detected by the MetalLB operator, which allocates an IP address as external IP for the service:
kubectl get services NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE hello-eks-a NodePort 10.101.120.84 <none> 80:31678/TCP 50m hello-eks-a-lb LoadBalancer 10.106.82.153 172.18.200.0 80:31354/TCP 46m kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 6h5m
Any node on the same layer 2 network can now access the service by its external IP address. Traffic is routed to one of the MetalLB speaker pods that in turn routes the traffic to a pod backing the service:
curl http://172.18.200.0 ----------------------------------------------------------------------------------------- Thank you for using EKS ANYWHERE You have successfully deployed the hello-eks-a pod hello-eks-a-866ff6bbc7-krtz4 For more information check out https://anywhere.eks.amazonaws.com -----------------------------------------------------------------------------------------
Unlike with NodePorts, any service can bind common ports like 80 or 443 regardless of other services in the cluster with MetalLB. However, this does not solve the task of registering the services’ external IP addresses with the clients or external DNS. This is especially challenging in a Microservice architecture.
Alternatively, we can deploy a single service as an ingress controller and use path-based routing for our application parts in the EKS cluster. Emissary Ingress from Ambassador [16] is the recommended ingress controller for EKS Anywhere. The controller provides an Envoy proxy as an entry point for our application. It is run as a regular deployment in Kubernetes and registers a service of the type LoadBalancer. Emissary Ingress installs a CRD of the type Mapping. This CRD can be used to register paths in the reverse proxy for individual services. When changes are made, the Emissary Ingress control plane updates the Envoy Proxy configuration. Figure 6 shows an example. You can find more details about installing and configuring Emissary Ingress in the EKS Anywhere documentation [17].
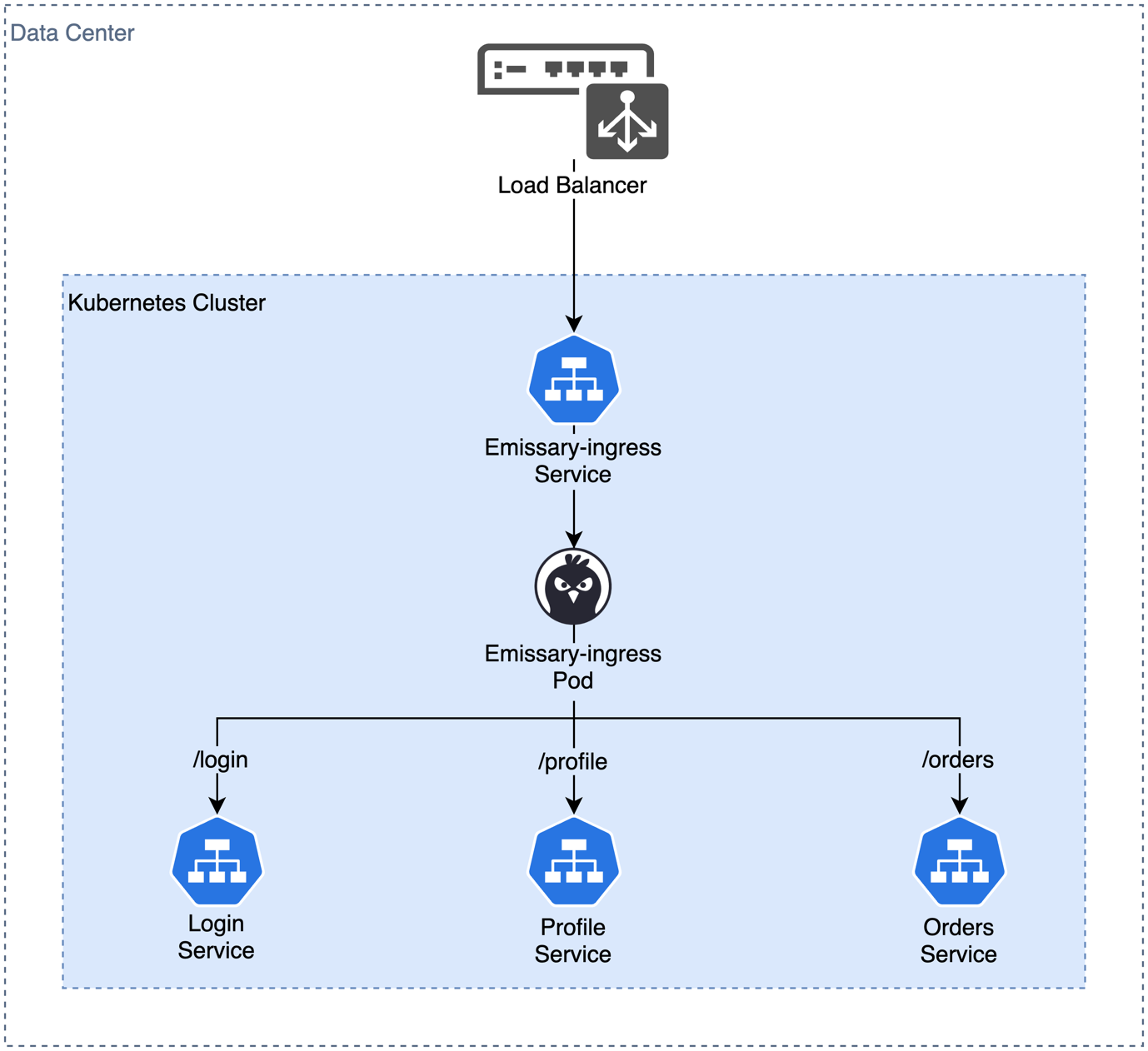
Fig. 6: Path-based routing with Emissary Ingress as reverse proxy
On-premises support from the SaaS provider
At this point, the SaaS provider has a target environment for deployments of its on-premises solution that bears a close resemblance to the familiar environment in the Cloud. This enables the software vendor to take more operational responsibility in the customer’s on-premises environment, roll out its processes used in the cloud, and truly offer its product as a service. But in order to do this, the software provider’s employees and systems must have access to the customer’s Kubernetes API. The following section shows how a lightweight integration can be done with a core component of EKS Anywhere.
If the software vendor offers its SaaS offering in AWS, it already manages users, roles and permissions in AWS Identity and Access Management (IAM) – or an external Identity Provider (IDP) integrated via AWS IAM Identity Center. The aws-iam-authenticator project [18] uses the Kubernetes option to perform authentication with WebHook tokens in order to integrate an existing user management in IAM with Role Based Access Contrl (RBAC) in Kubernetes. The Kubernetes cluster doesn’t need to have any integration with the Cloud. Only the public AWS API must be accessible through the cluster in order to validate tokens submitted by clients. Besides a separation of concerns – authentication by AWS IAM and authorization by Kubernetes RBAC – aws-iam-authenticator provides an audit trail (in AWS CloudTrail) and multifactor authentication for the Kubernetes API. Figure 7 shows the authentication and authorization workflow.
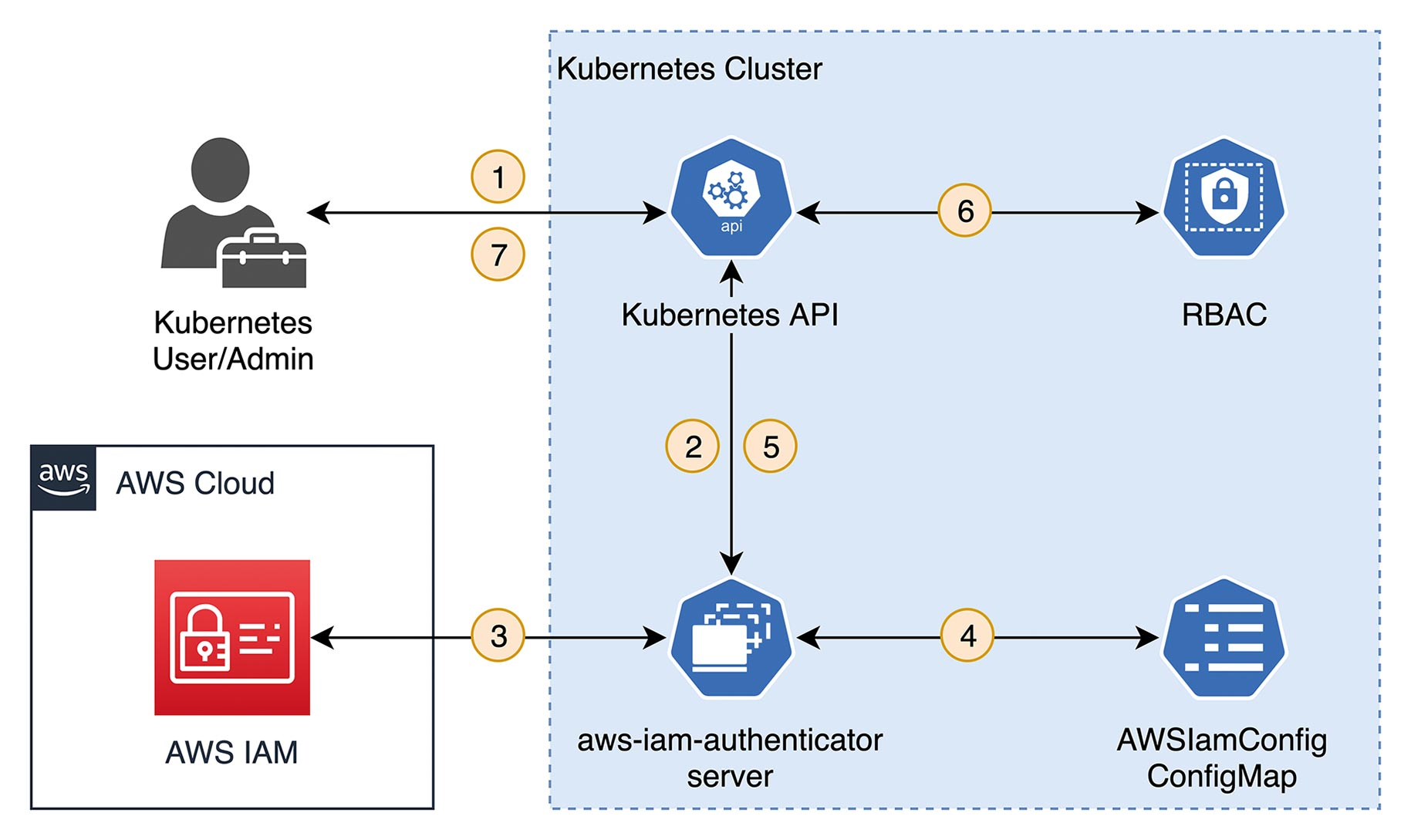
Fig. 7: Authentication and authorization with aws-iam-authenticator
For authentication with the aws-iam-authenticator, pre-signed URLs are used. This kind of URL allows certain actions to be performed against the AWS API – in the context of the AWS identity that generated the specific pre-signed URL. The presigned URL that the aws-iam-authenticator client generates grants permission to invoke the AWS interface sts:GetCallerIdentity. Callers are enabled to determine the unique Amazon Resource Name (ARN) of the AWS identity. This URL, along with other information such as the cluster ID, is converted into a token and submitted to the Kubernetes API (1 in Figure 7). The aws-iam-authenticator server component is installed as a DaemonSet in the Kubernetes cluster. It integrates with the Kubernetes authentication process via WebHooks (2). The token is validated before the pre-signed URL is used to determine the ARN (3). Now, a Kubernetes ConfigMap (AWSIamConfig) is searched for the mapping to a Kubernetes identity for this ARN (4). This completes the authentication process. The request comes from a valid AWS identity. And there is a Kubernetes identity in the cluster associated with it. The latter is returned to the Kubernetes API (5), which uses RBAC to check if the desired request (for example, launching a pod in a particular namespace) is allowed for the Kubernetes identity (6). Finally, the appropriate result of the call is returned to the client (7).
Learn more about Serverless Architecture ConferenceSTAY TUNED!
Listing 6 shows an example of the AWSIamConfig. Both IAM roles and users from different AWS accounts can be used. After successful authentication, the identities are mapped to users who can then be mapped to RBAC permissions using their group membership. Because the initial AWS user isn’t known when IAM roles are used, it’s a best practice to set a dynamic user name with additional context information to for the audit trail. You can find detailed information in the aws-iam-authenticator documentation [18].
Listing 6
apiVersion: v1
data:
mapRoles: |
- roleARN: arn:aws:iam::000000000000:role/KubernetesAdmin
username: admin:{{SessionName}}
groups:
- system:masters
mapUsers: |
- userarn: arn:aws:iam::111122223333:user/admin
username: admin
groups:
- system:masters
- userarn: arn:aws:iam::444455556666:user/ops-user
username: ops-user
groups:
- eks-console-dashboard-full-access-group
To use the workflow described above, you must enable the aws-iam-authenticator when creating the cluster. Do this by extending the cluster template from Listing 1. The official documentation [19] describes the relevant sections. Alternatively, OIDC providers can be used for authentication [20] via other external IDPs.
Conclusion
When converting a product to a SaaS offering, software vendors often face the question of how to realize a deployment for Cloud and on-premises environments in parallel. In both parts of this article series, we looked at the hybrid deployment of SaaS solutions. We looked at Amazon ECS Anywhere and Amazon EKS Anywhere, two solutions that let software vendors use the operating processes and tools used for their Cloud-based offerings in on-premises environments as well.
Links & Literature
[1] https://www.redhat.com/en/resources/kubernetes-adoption-security-market-trends-2021-overview
[3] https://docs.aws.amazon.com/eks/latest/userguide/managed-node-groups.html
[4] https://docs.aws.amazon.com/eks/latest/userguide/fargate.html
[5] https://github.com/aws/containers-roadmap
[6] https://www.infoworld.com/article/3574853/kubernetes-and-cloud-portability-its-complicated.html
[7] https://distro.eks.amazonaws.com
[9] https://github.com/bottlerocket-os/bottlerocket
[10] https://cluster-api.sigs.k8s.io/introduction.html
[11] https://kind.sigs.k8s.io/docs/user/quick-start/
[12] https://anywhere.eks.amazonaws.com/docs/reference/baremetal/bare-prereq/
[13] https://anywhere.eks.amazonaws.com/docs/getting-started/install/
[14] https://anywhere.eks.amazonaws.com/docs/reference/clusterspec/
[15] https://metallb.universe.tf
[16] https://www.getambassador.io/docs/emissary/
[17] https://anywhere.eks.amazonaws.com/docs/tasks/workload/ingress/
[18] https://github.com/kubernetes-sigs/aws-iam-authenticator
[19] https://anywhere.eks.amazonaws.com/docs/reference/clusterspec/iamauth/
[20] https://anywhere.eks.amazonaws.com/docs/reference/clusterspec/oidc/




