
Function as a Service (FaaS) is the easiest way to run code in the cloud. It also allows you to benefit from the advantages of a managed environment such as automatic scaling, high availability and fault tolerance without incurring initial overhead and long-term costs. That’s why FaaS lends itself very well to irregular, fault-tolerant and short-term services with high scalability at low cost. No server needs to be provisioned, managed, patched or updated for this. As long as the code is running, only pure consumption is paid for. Because no server is easier to manage than simply no server at all. Who needs servers when there are services?
But how can you reduce dependency on one vendor and keep costs under control? How can you achieve the desired quality goals such as security, responsiveness and monitorability and integrate development and deployment into existing DevSecOps processes?
Learn more about Serverless Architecture ConferenceSTAY TUNED!
What is Serverless Computing?
Serverless computing is still a new and rapidly evolving discipline (Clark, Libby; Finley, Klint: „Guide to Serverless Technologies“), (CNCF WG-Serverless Whitepaper v1.0). The idea is that you only have to worry about the creation and configuration of the function, but not about its scaling and the required resources. That is why one only pays for the real consumption and not for the infrastructure provided. However, since one has to share the infrastructure with others despite isolation, the execution time of the function may fluctuate. The vendor-independent λ Serverless Benchmark can serve as an initial orientation.
In terms of infrastructure, serverless computing is based on containers, whereby these are becoming smaller and thus faster as nanocontainers. In terms of programming, they are based on events and functions. Up until now, a standard has only been developed for events with the CNCF cloud events specification in order to be able to implement serverless with multi-cloud environments – also from different manufacturers – and as hybrid clouds. That is why, up to now, programming and operation have mostly been tied to one cloud provider and its model. In order to move from Function as a Service (FaaS) to serverless computing, it is important that the cloud provider also makes more and more of its services available serverless for direct use. For higher-value services such as databases, these can still be integrated as Backend as a Service (BaaS).
Most of the time FaaS are stateless. However, the call of a function can depend not only on an event, but also on a state. For this purpose, there is the serverless function workflow. Such a state machine is called Step Functions (CNCF WG-Serverless Whitepaper v1.0) in AWS Lambda, for example. It is mainly used when functions are executed in parallel, but they have to synchronize with each other. It distinguishes between the states of the event, the operation, or the condition. As with every state graph, there is a defined start and end state. There are also the possibilities to delay the event processing or to wait for the result. Step Functions not only provide a graphical modeling component to represent such dependencies. It even offers the possibility to visualize the respective state of the nodes. This provides an overview of the execution of the respective function at any time.
For function calls, there are the following ways to implement different use cases:

- synchronous blocking calls (Req/Rep), e.g., HTTP, gRPC.
- asynchronous message-oriented calls (Pub/Sub), e.g., MQ, AWS SNS, MQTT, email, object store changes (S3, Ceph), scheduled events as in cron jobs
- Message/data streams, e.g., AWS Kinesis, AWS DynamoDB streams, Database CDC
- Batch jobs, e.g. ETL jobs, distributed deep learning algorithms, HPC simulations.
This allows typical serverless applications such as event-oriented data processing, web, mobile or Internet-of-Things services to be implemented. This is why BaaS, FaaS and serverless are always closely related in larger use cases (Fig. 1); in this way, the optimum solution can be found for the respective requirement.
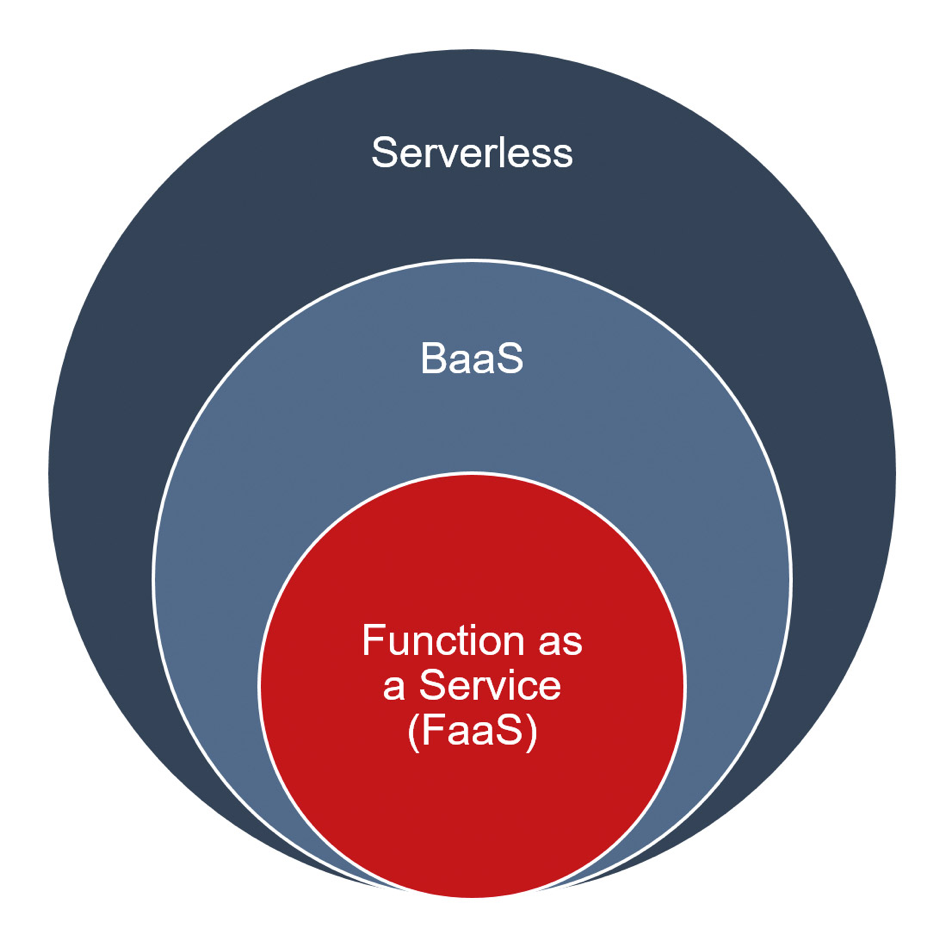
Serverless computing is made up of several components (FaaS and BaaS), as Figure 2 shows, and is closely interwoven with the offering of the respective cloud provider.
Beware of stumbling blocks
To prevent “services without servers” from becoming a nightmare, there are some stumbling blocks to avoid. The biggest challenges for serverless services cited in a survey (Passwater, Andrea: „2018 Serverless Community Survey: huge growth in serverless usage“) were: the use of best practices, lack of tool support, knowledge gaps in the team, vendor dependency, and cost (Fig. 3).

Since scripting languages such as Node.js and Python have a shorter startup time with lower resource consumption, they are more suitable for existing knowledge than established interpreter languages such as Java or C#. In addition, both are supported by all cloud providers and there is now a broad ecosystem around scripting languages. The problem of cold start times, on the other hand, is negligible for most use cases. More significant is how to leverage third-party libraries. For example, with Lambda, AWS provides layers to share shared libraries and other dependencies between different Lambda functions. This has the advantage of making functions start faster and consume fewer resources. This is because the shared dependencies only need to be loaded once and are therefore usually already there. Moreover, if these layers respect the maximum size, they are not charged. With the Serverless Framework, there is an abstraction layer to use the most popular serverless platforms such as AWS, Azure, and GCP in a more unified way. Unfortunately, however, support for the individual platforms varies widely and is still missing for Knative (as a successor to Kubeless), for example, so the Serverless Framework really only makes sense for AWS, although here AWS offers its own powerful alternative with the Serverless Application Model (SAM). Platform independence, as well as skills and suitable tools, remains a challenge in the development of serverless services when dealing with a multicloud environment.
Serverless does not mean headless
Just as it’s a myth that the cloud is always cheaper than self-powered solutions, the same is true for serverless services. As is often the case, it depends on the requirements, the particular use cases and the implementation. Even if the use case is a good fit for serverless, small mistakes can have a big impact. That’s why it’s important to know and monitor your overall architecture, so you can identify the emergence of unnecessary costs early on and take countermeasures. This starts with security. Even though some of the typical OWASP vulnerabilities (OWASP Serverless Top 10 Project) are less relevant for serverless services, there are again new challenges such as the “attack your wallet” attack target. Here, one should know and apply the general best practices (such as from OWASP) and the specific ones of the vendors. It is to be welcomed that there is a practice project here, e.g., with OWASP ServerlessGoat for AWS Lambda (AWS: „Serverless Applications Lens. AWS Well-Architected Framework“), (AWS: „Security Overview of AWS Lambda“), in order to be able to identify and thus fix security vulnerabilities for serverless services as well.
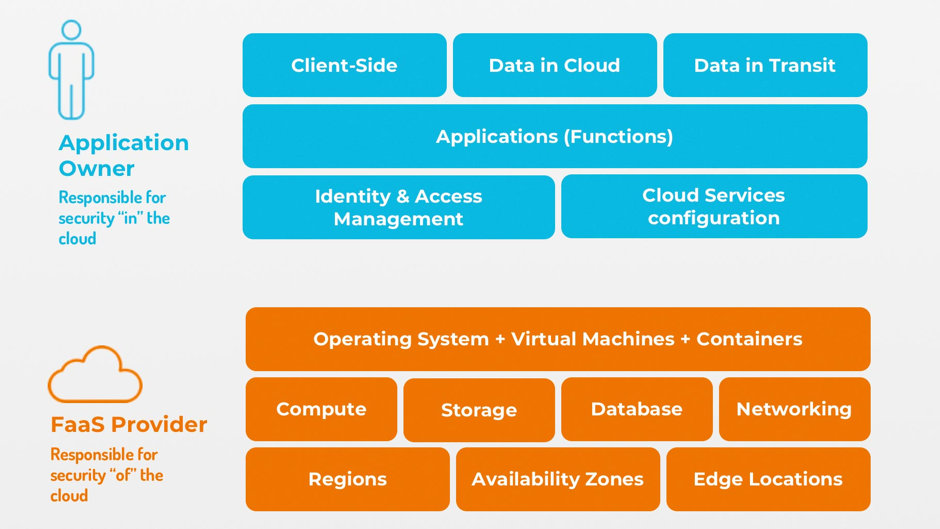
Similar to other cloud offerings, a shared responsibility model applies to serverless services (Fig. 4). Serverless does not mean carefree.
Some security risks are lower than the well-known OWASP Top 10 (2017) for web applications, but others, such as misuse of third-party computing power (SAS-08) or spying on credentials (SAS-04, -03, -07), can have unpleasant consequences, not only for the serverless function, but for the entire application. PureSec has summarized the current top 10 security risks of serverless (CSA: „The 12 Most Critical Risks for Serverless Applications“):
- SAS-01: function event-data injection
- SAS-02: broken authentication
- SAS-03: insecure serverless deployment configuration
- SAS-04: over-privileged function permissions and roles
- SAS-05: inadequate function monitoring and logging
- SAS-06: insecure third-party dependencies
- SAS-07: insecure application secrets storage
- SAS-08: denial of service and financial resource exhaustion
- SAS-09: serverless business logic manipulation
- SAS-10: improper exception handling and verbose error messages
- SAS-11: legacy/unused functions and cloud resources
- SAS-12: cross-execution data persistency
The larger the functions become, the more important the management of the vulnerabilities of the third-party libraries, sufficient (but not too treacherous) logging and exception handling. Here, companies that already know these challenges from distributed microservices in the cloud, already take into account the twelve factors popularized by Heroku and regularly check them in a DevSecOps pipeline have advantages.
Serverless is not free
Although it may sound tempting at first, larger serverless solutions incur significant costs (Rogers, Owen: „The economics of serverless cloud computing“) when using both backend and infrastructure services. With dependency costs to the chosen provider, it is not always worthwhile to spend more effort on portability testing or additional abstractions. Here, one often has to weigh the effort against the benefit. For this reason, Wisen Tanasa (Tanasa, Wisen: „Mitigating serverless lock-in fears“) recommends comparing the potential migration costs with the benefits realized with the services before switching to another serverless provider. Thus, a change of provider would only make sense if the operating costs were significantly reduced and the benefits (e.g., synergy effects of a uniform cloud platform) were significantly higher than the migration costs incurred.

Learn more about Serverless Architecture ConferenceSTAY TUNED!
Conclusion
Ten years after the “A Berkeley View of Cloud Computing” paper, Berkeley University predicts in its latest paper (Jonas, Eric et al.: „Cloud Programming Simplified: A Berkeley View on Serverless Computing“), (Hellerstein, Joseph M et al.: „Serverless Computing: One Step Forward, Two Steps Back“: 2019) that serverless computing will become the standard way to perform functions in the cloud era. In doing so, serverless complements and accelerates cloud usage. The industrialization and standardization of cloud-native services is also progressing under the CNCF Foundation umbrella. It will be exciting to see whether Knative with CloudEvents can achieve a similarly large spread as Kubernetes, or whether Amazon in particular will continue to cook its own cloud soup. It would be desirable that serverless computing (FaaS and BaaS) becomes part of every normal architecture construction kit in order to expand the solution space with new use cases.




