
GraalVM is a high-performance runtime environment that can drastically reduce the startup times and memory requirements of applications using native images. Both factors are essential for short-lived and fast-scaling serverless functions. In this article, we’ll take a closer look at how GraalVM Native Images work in the context of AWS Lambda Functions.{.preface}
We will also learn the difference between managed AWS Lambda runtimes such as Java 17 and the custom runtimes required for GraalVM, as well as what additional tools, configurations and libraries need to be integrated into the development process.
Why serverless functions?
Serverless functions allow developers to focus on programming their business logic instead of managing complex infrastructures. Compared to orchestrated container deployments, where a multitude of configurations are required to run an application, serverless functions usually only need a basic configuration of memory or CPU and the application code. High availability, automatic scaling and security mechanisms are provided by the platform. In the context of AWS Lambda, a serverless function service from Amazon Web Services (AWS), a function can be integrated directly with other components, such as an API (via Amazon API Gateway), queue (Amazon SQS) or streaming services such as Amazon Kinesis or Apache Kafka, without having to write glue code (e.g. for polling).
In addition, serverless functions are usually billed based on usage (memory x milliseconds) and scale to zero. Therefore, a function that isn’t executed generally doesn’t incur any costs.
Challenges of serverless functions
However, scaling to zero poses some challenges. If no active instance is available when a function is called, it must first be created. AWS Lambda is based on Firecracker MicroVM technology, which creates a dedicated, isolated execution environment for a Lambda function. The first time it is called, such an execution environment is created, the Java Virtual Machine (JVM) is started in it and the application code is loaded and initialized. This process usually only takes a few hundred milliseconds for a simple Java application. However, for more complex applications that integrate a framework and load larger libraries, for example, this process can take several seconds.
The creation and initialization of a new execution environment – if no other is available – is also known as a cold start in this context. As soon as a function has been initialized and the MicroVM and the initialized code are available, a subsequent request can reuse this environment. In this case, only the application code or business logic is executed without initialization and the runtime is identical to a containerized application (warm start) (Fig. 1).
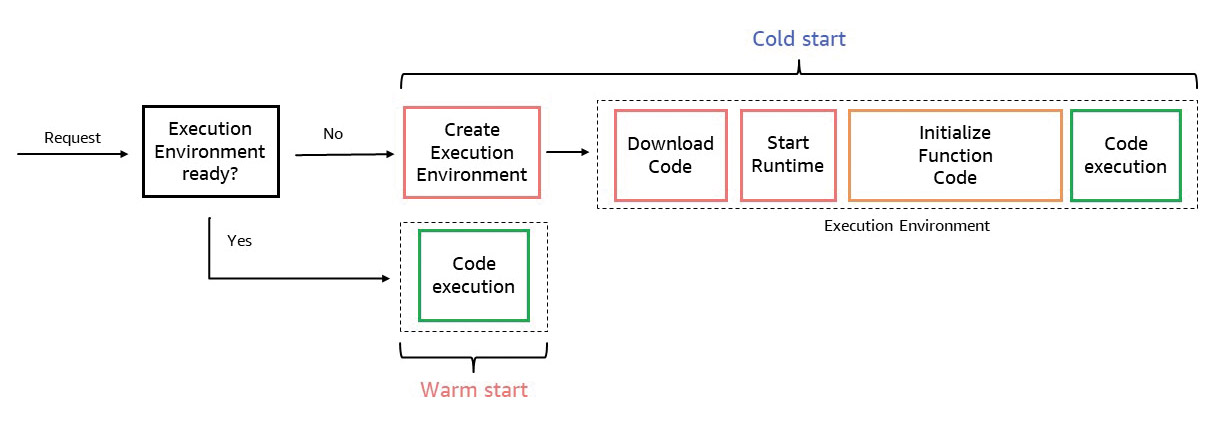
Fig. 1: Cold and warm start of execution environments for serverless functions{.caption}
At this point, it is important to note that a cold start occurs not only when no execution environments are available, but also when already initialized execution environments are currently processing a request. Put simply, an execution environment can only process a single request at a time (there is no multi-threading as we know it from classic Java application servers). If two requests were to reach our application at the same time, two execution environments would be initialized and therefore each request would also cause a cold start. Afterwards, both execution environments remain initialized for a certain period of time so that they can be used for subsequent requests (Fig. 2).
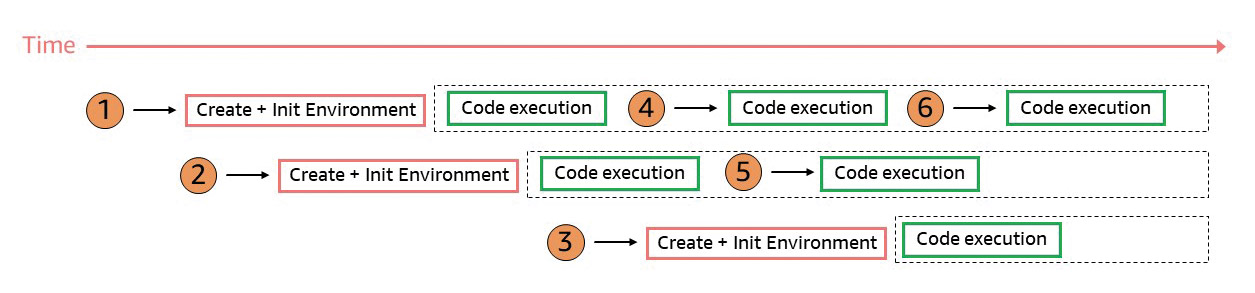
Fig. 2: Execution environments for parallel requests{.caption}
Another important factor with serverless functions is the memory requirement. As already mentioned at the beginning, the pricing model for AWS Lambda consists of two components: Duration of a request (in milliseconds) and amount of memory (in MB). CPU and network are not considered separately, as these are proportionally based on the memory configuration. To calculate the cost of a request, the execution time is multiplied by the working memory. A function with 1024 MB of RAM is therefore 50 percent cheaper than a function with 2048 MB. A lower memory requirement therefore leads to significant cost advantages.
Some components of the Java Virtual Machine (JVM) require a certain (partly predefined) amount of memory. In addition to the Java heap, which manages the objects at runtime, the garbage collection, the just-in-time (JIT) compiler and codecache require additional memory. This can lead to increased memory consumption compared to natively compiled or interpreted programming languages, especially when the JVM is initially started. However, as we have already seen, the initial phase in particular is crucial for short-lived and fast-scaling functions.
Possible solutions
To address the challenges of startup times and memory consumption of the JVM, the Java ecosystem offers several solutions and current development projects. We would like to highlight two solutions in the following section.
CRaC and AWS Lambda SnapStart
Coordinated Restore at Checkpoint (CRaC) is an OpenJDK project that deals with mechanisms to checkpoint a JVM during execution and create a snapshot of this state. Restoring this image is faster than reinitializing and thus helps to minimize cold starts. As part of the project, a new standard API was also developed to inform Java programs about checkpoint and recovery events and, for example, to execute code to reinitialize a network connection.
AWS Lambda SnapStart supports this standard API and uses a similar mechanism based on Firecracker snapshot technology to improve the startup time for Serverless Java Functions by up to ten times. Lambda creates a Firecracker-microVM snapshot of the initialized execution environment, encrypts the snapshot and stores it in a cache that can be accessed with low latency. When a function version is called for the first time or parallel requests require scaling, Lambda resumes new execution environments from the snapshot stored in the cache instead of reinitializing them from scratch. As a result, the cold start time is reduced.
GraalVM
GraalVM is a JDK that accelerates the execution of applications written in Java and other JVM languages, but also provides runtimes for other languages such as JavaScript or Python. GraalVM offers two ways to run Java applications: on the HotSpot JVM with Graal’s JIT compiler or as a pre-compiled executable native image. With polyglot capabilities, GraalVM can also run multiple programming languages in a single application, eliminating the cost of foreign language calls.
The native image is particularly suitable for shortening cold starts. This is created by an extended build process using ahead-of-time compilation (AOT) and is operating system-dependent. This means that a JVM is no longer required for execution. As native machine code is available, the function starts in a fraction of the time and also requires significantly less memory. However, there are also limitations with regard to the dynamic possibilities known from Java at runtime. For example, the popular Reflection API can no longer be used to search for classes at runtime; instead, such calls must be resolved by static code analysis when the application is built. We’re not covering SnapStart and other optimizations here, but we’ll focus on the implementation with GraalVM in the remainder of this article.
Implementation
To create a GraalVM Native Image for AWS Lambda, you’ll want to do the following:
- Installation of GraalVM and the native image tool or use of a build container
- GraalVM Maven or GraalVM Gradle plug-in to automate the build process
- Configuration and creation of an AWS Lambda Custom Runtime
- Additional configuration of dynamic dependencies (optional)
The steps described below can be followed and executed in an interactive workshop:
1. Installation of GraalVM and native image or use of a build container
To create a GraalVM native image, GraalVM and the native image tool must first be installed. The tools can first be installed in the build environment to test the build. However, as native images are specific to the operating system or processor architecture, they must be built for the target platform. For example: A GraalVM native image is executed on AWS Lambda in a custom runtime (see point 3) based on Amazon Linux 2 (either on x86 or arm64). The native image must therefore be built specifically for this platform. To execute the build for the target platform (Amazon Linux 2 + arm64), a container image including Amazon Linux 2, GraalVM, native image tool and Maven/Gradle can be used and the build process (e.g. mvn package) can be delegated to the container. Finally, the native binary can be extracted from the container or placed in a linked directory directly after the build process in order to use it for later deployment (Fig. 3).
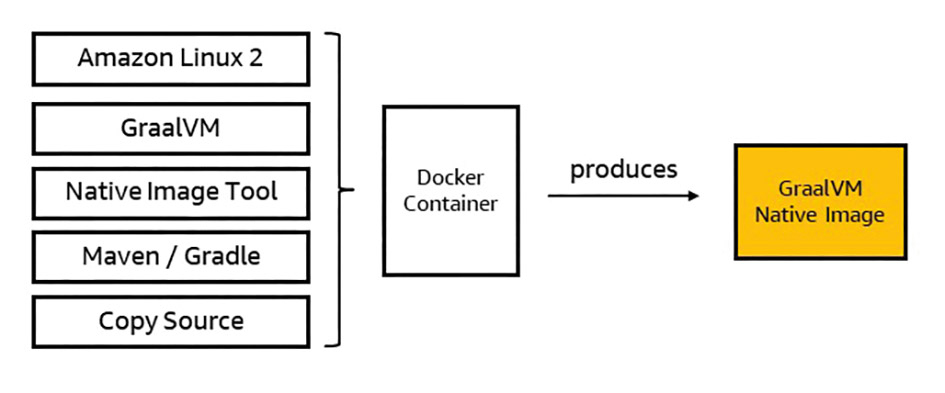
Fig. 3: Build process for a GraalVM native image{.caption}
2. GraalVM Maven or Gradle plug-in to automate the build process
The native image build can be automatically integrated into existing Java build tools such as Maven or Gradle using the official plug-ins. It is advisable to outsource the native image build to a separate Maven profile, for example, so that the build process can be controlled individually. An example with the native-maven-plugin can be found in Listing 1. After executing mvn -Pnative package, the native image is created without an additional call to the GraalVM tools. The plug-in automatically determines which JAR files must be included in the native image and which is the class with executable main method (individual configuration adjustments are of course possible).
Listing 1
``` <profile> <id>native</id> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>3.4.1</version> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <transformers> <transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"> <mainClass>com.amazonaws.services.lambda.runtime.api.client.AWSLambda</mainClass> </transformer> </transformers> <shadedArtifactAttached>true</shadedArtifactAttached> </configuration> </execution> </executions> </plugin> <plugin> <groupId>org.graalvm.buildtools</groupId> <artifactId>native-maven-plugin</artifactId> <version>0.9.22</version> <extensions>true</extensions> <executions> <execution> <id>build-native</id> <goals> <goal>build</goal> </goals> <phase>package</phase> </execution> </executions> <configuration> <skip>false</skip> <imageName>native</imageName> <buildArgs> <buildArg>--no-fallback</buildArg> </buildArgs> <classpath> <param>${project.build.directory}/${project.artifactId}-${project.version}-shaded.jar</param> </classpath> </configuration> </plugin> </plugins> </build> </profile> ```
In addition to the native-maven-plugin, the profile contains the maven-shade-plugin to create a single Uber JAR that contains all the necessary dependencies. The complete, executable example can also be found in the Git repository of the aforementioned workshop.
3. Configuration and creation of an AWS Lambda custom runtime
Since we work with native binaries in GraalVM instead of a traditional Java Virtual Machine with JAR or classpath start instructions, we need a custom runtime in the context of AWS Lambda.
In addition to managed runtimes (e.g. Java 11, Java 17, Python 3.10, Node.js 18), AWS Lambda also offers the option of creating your own custom runtime. As an example: With a Java 17 runtime managed by AWS, the JVM is already provided by the AWS Lambda Service and developers only have to deliver the code. With a custom runtime, however, all components required to run the application must be delivered (runtime + code).
In addition, communication must be established between the Custom Runtime and the AWS Lambda Service. AWS Lambda provides the AWS Lambda Runtime API for this purpose. The Runtime API defines a standard for custom runtimes to receive new requests from Lambda and to return the corresponding responses after successful execution. Error handling is also controlled via the API. To avoid having to implement this integration manually for each custom runtime, AWS provides ready-made runtime interface clients (RIC) as Java libraries. In this case, only the RIC library needs to be added to the project and communication with the AWS Lambda Runtime API is guaranteed.
Finally, the AWS Lambda Service requires instructions on how to start a custom runtime. These instructions are defined in a bootstrap file. This file usually contains shell commands and parameters to execute the custom runtime (analogous to ENTRYPOINT or CMD in Dockerfiles). AWS Lambda calls up the bootstrap file at startup and executes the commands defined in it (Fig. 4).
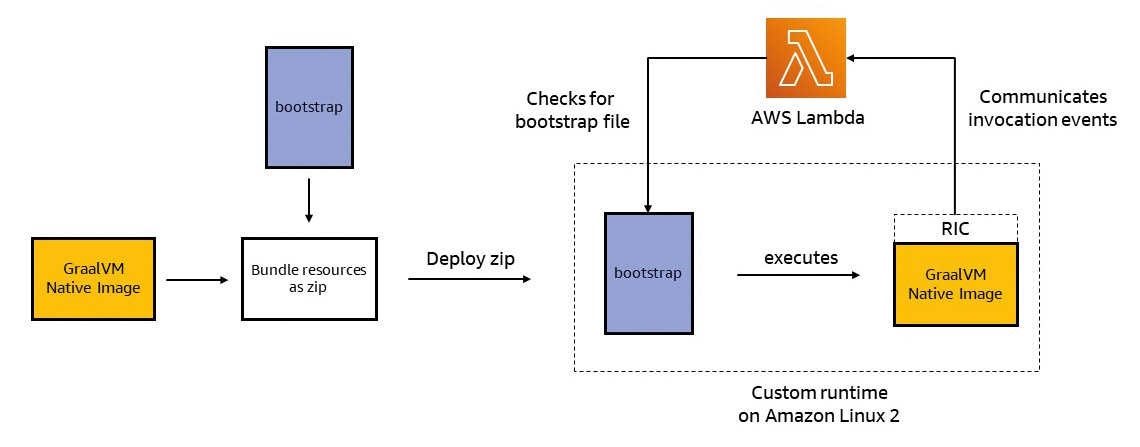
Fig. 4: Interaction between GraalVM Native Image and AWS Lambda Custom Runtime{.caption}
4. Additional configuration of dynamic dependencies (Optional)
A closer look at the referenced Git repository may reveal files such as jni-config.json, native-image.properties, reflect-config.json or resource-config.json. These reachability metadata configurations provide GraalVM with assistance for dynamic dependencies that cannot be resolved using static code analysis.
Ideally, the creators of frameworks and libraries would include this metadata directly. However, GraalVM has not yet achieved the degree of widespread use that would allow it to be taken into account everywhere. Thus, the limitation of dynamic functionalities at runtime in combination with missing metadata represents a main challenge for the use of GraalVM. An agent can be used to generate the missing metadata yourself. A community repository, in which GraalVM users can share metadata is another remedy.
Comparative benchmark
In the following benchmark, we tested the sample application from the workshop mentioned above in the different configurations. The application uses the AWS SDK v2 and writes entries to an Amazon DynamoDB database table. The Java 17 Managed Runtime from AWS (without SnapStart) and a GraalVM Native Image in the Custom Runtime were tested. In the test, the same AWS Lambda function was called in different memory configurations with 50 calls per second for five minutes (15,000 requests in total). The p90 percentile of the performance was used for the illustration in Figure 5.
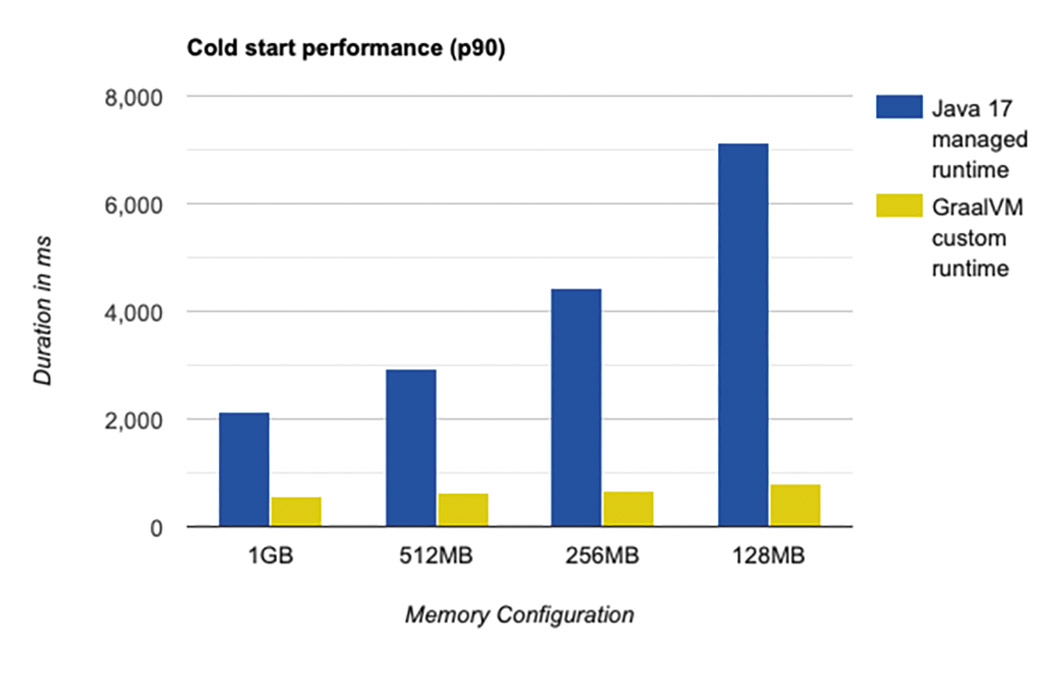
Fig. 5: Cold start performance comparison{.caption}
Based on the results, we can see that GraalVM Native Images lead to a drastic reduction in cold starts. In addition, a lower memory configuration for the GraalVM Native Image variant of the application only has a minimal effect on performance. At warm start, we only see a slight performance optimization (in the millisecond range) with the higher memory configurations compared to the managed Java Runtime. In the lower memory range, however, the GraalVM native images show their advantages (Fig. 6).
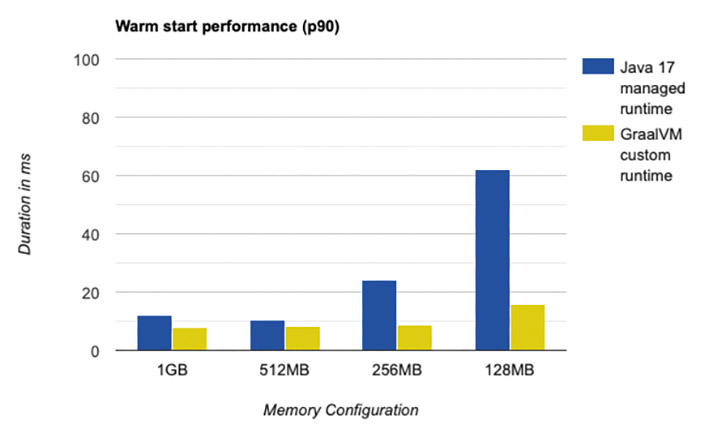
Fig. 6: Warm start performance comparison{.caption}
It is important to note at this point that the number of warm starts (under constant load) is usually significantly higher compared to cold starts. As described above, this is because the newly initialized execution environments can be reused by subsequent requests for an indefinite period of time. As an example: In the benchmark described above, on average less than 1 percent of all requests are cold starts, as after the first 50 parallel requests, several execution environments are available for the next 50 requests. For productive use, it is therefore important to weigh up how heavily cold start performance should be weighted in the context of overall performance.
Conclusion
With GraalVM, we can shift part of the resource utilization from the execution phase of the application to the build phase. The time and memory requirements at runtime are reduced, but significantly more time and memory is required for the build process (CI/CD systems may have to be scaled accordingly). Overall, GraalVM is well suited to reducing the memory requirements of Java applications and addressing the problem of cold starts. In terms of resource utilization, this is more efficient than deliberately keeping a number of functions warm (using provisioned concurrency). Nevertheless, this functionality can of course also be combined with GraalVM for very latency-critical applications in order to completely eliminate cold starts.
However, depending on the functionalities, libraries and frameworks used in the Java application, GraalVM may result in additional configuration work that should not be underestimated, and in some cases (e.g. when generating bytecode at runtime) it cannot be used. The test procedure must also be adapted, as a native image is used instead of a classic JVM for execution. Well-known frameworks such as Micronaut, Quarkus, and Spring Boot 3 abstract the complexity of GraalVM and make it easier to utilize its advantages.
Links & Literature
[1] AWS Lambda: https://aws.amazon.com/lambda/
[2] Firecracker: https://firecracker-microvm.github.io
[3] CRaC: https://openjdk.org/projects/crac/
[4] GraalVM: https://www.graalvm.org
[5] Workshop Accelerate Serverless Java with GraalVM: https://s12d.com/aws-serverless-graalvm
[6] Maven plugin configuration for GraalVM Native Image building: https://graalvm.github.io/native-build-tools/latest/maven-plugin.html#configuration
[7] AWS Lambda Java Workshop Repository: https://github.com/aws-samples/aws-lambda-java-workshop/
[8] GraalVM Native Image Reachability Metadata: https://www.graalvm.org/latest/reference-manual/native-image/metadata/
[9] GraalVM Collect Metadata with the Tracing Agent: https://www.graalvm.org/latest/reference-manual/native-image/metadata/AutomaticMetadataCollection/
[10] GraalVM Reachability Metadata Repository: https://github.com/oracle/graalvm-reachability-metadata
[11] AWS Lambda Provisioned Concurrency: https://docs.aws.amazon.com/lambda/latest/dg/provisioned-concurrency.html
[12] Micronaut Graal Guide: https://guides.micronaut.io/latest/micronaut-creating-first-graal-app.html
[13] Quarkus Building a native executable: https://quarkus.io/guides/building-native-image
[14] Spring Boot GraalVM Native Image support: https://docs.spring.io/spring-boot/docs/current/reference/html/native-image.html




