Of course, serverless does in fact require servers, but these are so far abstracted from the user’s point of view that you no longer have to worry about provisioning and scaling. That said, serverless is not suitable for every application. In this article, we discuss the advantages and disadvantages of serverless, as well as some guidance in the form of a six-point list to bear in mind if you want to adopt the serverless paradigm. We also show when it is not the right choice.
Learn more about Serverless Architecture ConferenceSTAY TUNED!
What makes us think serverless is so special? Is it just another hype that will soon be over? We don’t believe so. Developers and system administrators know how hard it is to manage infrastructure, and how much you need to know and take into account. Many attempts to introduce microservices in companies have failed, especially in the data center, because the need for different infrastructure has grown significantly (“Use the right tool for the job.”) and companies wanted to run the operation themselves. However, operating a NoSQL database yourself is not so easy, for example.
In addition, the focus is often on (naturally important) issues such as operability, instead of first asking oneself what problem the company actually wants to solve. Often the answer is that in these fast-moving times of digitization, companies want to deliver high-quality features in the core areas of their applications at a fast pace. Of course, the non-functional requirements such as operability are part of it, but customers take these for granted.
All that matters to the customer is that the application runs. Rarely is the infrastructure and its operation the core business of the company, unless it is a cloud or data center provider. Serverless helps to put the focus back on the business logic. Another advantage of the serverless paradigm is the automatic scaling together with the pay-per-use model. In our company ip.labs GmbH we have gained the painful but also valuable experience of what it means to manage infrastructure yourself and to take care of the scaling ourselves. We experience large peaks during the holidays (because this is the time when most photo products are ordered, such as photo books with the year’s highlights, or annual calendars). Since our company operates in the business-to-business segment, we are also dependent on forecasts from our customers, which are naturally inaccurate. However, the planning for a data center must be done in advance, which involves great financial risks. Capacity planning is a real challenge and also rarely the core business of the company. It is a huge help when the cloud provider takes over. With serverless, we typically try to link serverless services to each other in order to write as little code as possible. And the less code you write yourself, the less you have to maintain yourself; less technical debt means more new functionality you can create with the same team. Paul Johnston sums this up with his quote: “Whatever code you write today is always tomorrow’s technical debt”; How often have we seen that developers feel little ownership of their own code after just one year because outdated paradigms, frameworks or programming languages have been used? Upgrades are seldom given time and are difficult to justify to management unless there is a security vulnerability or it is some important component in the End of Support status. You get stuck in the long run when maintaining your own code.
However, if you are forced to upgrade, this is often difficult and costly. In most cases, not only the programming language version needs to be upgraded, but often also the version of the application server and most of the dependencies, which in turn often have their own dependencies. Product owners then rightly ask to what extent it improves the product.
The maintenance situation frustrates many developers, especially when their colleagues come into contact with modern and value-adding technologies through a different approach. Companies often overlook an important aspect: The costs of maintaining the software throughout its entire life cycle significantly exceed the development costs. The way out is here: Write as little code as possible to complete the task and use as few external dependencies as possible. The whole package (infrastructure, scalability, configuration and fault tolerance) should be left to the platform vendor. But what companies gain from this is immense – a focus on the essentials, a fast time to market and more time for innovation. This is exactly what all companies want and this is exactly what the serverless paradigm promises (we’ll talk about the hurdles later). For these advantages, one can also accept the trade-off of increased costs from the provider.
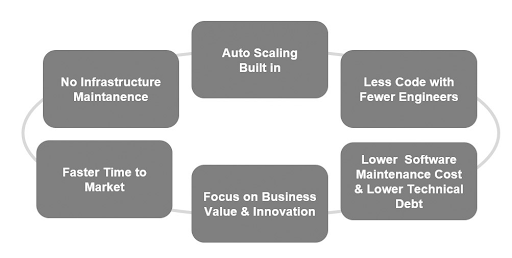
Total Cost of Ownership (TCO) of the serverless paradigm
To FaaS or not to FaaS? The decision list
We have prepared a list to help you decide whether serverless is the right paradigm for your organization, your business, your application, or your use case. It is not our goal to give you all the answers, but to draw your attention to certain challenges that need to be overcome. For general challenges we outline possible solutions. We will be focusing on AWS Cloud, especially when it comes to terms and solutions, because that is where we have the most knowledge and experience.
The decision list consists of the following items:
- Application life cycle
- Architecture and properties of the application
- Platform and Service Restrictions
- Company knowledge
- Cost structure of serverless applications
- Platform and tooling maturity
Application life cycle
Let’s start with understanding the application lifecycle. It basically consists of two phases (Fig. 2): research (explore) and use (exploit)
For the research phase it is important to:
- Validate hypotheses quickly
- Experiment quickly
- Conduct experiments as inexpensively as possible
The serverless paradigm is ideally suited here, since on the one hand speed advantages can be exploited (most of the infrastructure work is done by the cloud provider of our choice), while on the other hand cost advantages can also be brought into play. Only that which is actually used is paid for. You don’t have to pay the rather expensive on-demand prices for the infrastructure, or the reservation of the infrastructure (typically for one or three years), which is cheaper compared to on-demand instances, but has to be planned in advance. We ourselves do not know whether our hypotheses are true.
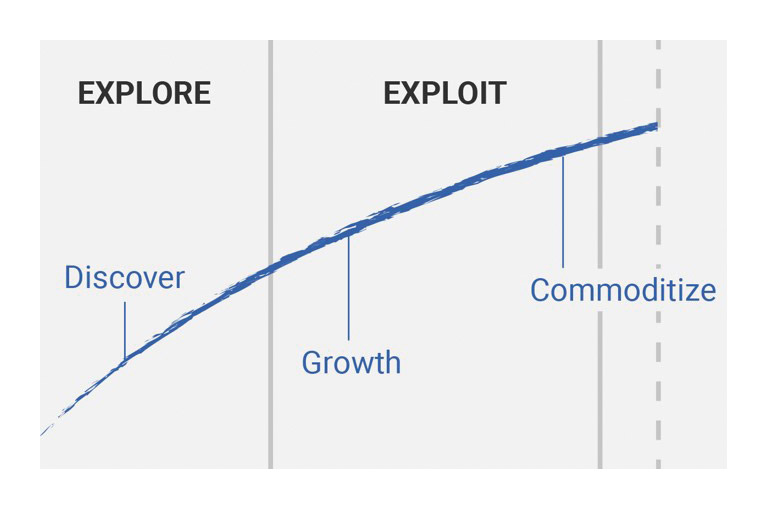
Application life-cycles
If we see that we can build a profitable product from our ideas and hypothesis (utilization phase), the following questions arise for us: How much of my stack should I own in order to achieve business value? Does the company want to completely outsource SLA, regulatory compliance, pricing, support and roadmap to my service provider? Many companies do not feel comfortable with relying on many managed services and not having these issues under control. Especially when your own product has reached a certain market maturity and already has many users.
This includes a very large portion of trust in the selected providers, and they must be able to justify this trust. If one of the features reaches the limits of scalability of one of the serverless services, one can either look for comparable alternatives from the same provider or use a different paradigm. Cost control in serverless applications is no longer so trivial, because these costs can be extremely high if the corresponding processes are not established.
In the utilization phase, most companies will seek a balance between serverless and other architectures and paradigms. In addition, many companies already have applications in use and cannot afford the complete rewriting. However, it is the desire of each individual company to build up speed in its core areas. Paradigms like serverless certainly contribute to such a modernization of the existing application.
One of the established methods is the Strangler Pattern, which Martin Fowler coined some years ago. From a certain point in time, it is a matter of no longer implementing new core functionalities in the old inflexible architectures, but of taking new paths. We achieve this by placing a kind of proxy between legacy application and user, implementing new functionality or services decoupled and connecting them to the proxy. In AWS you can use an API gateway and since one year also an Application Load Balancer (ALB) as proxy to implement the business logic with serverless managed services.
Architecture and properties of the application
We come to the next point: Understanding the architecture and properties of the application. An event-driven architecture for serverless is a natural choice. Serverless also fits very well for API-driven applications. However, the API Gateway cost can be very high if there are a lot of requests (API Gateway is priced at $3.5 per million requests). We will take a closer look at this when we talk about the costs. However, it is possible to rely on ALB as well as on the recently introduced, much cheaper HTTP APIs for Amazon API Gateway (currently in preview).
In both cases, certain functionalities are omitted (e.g. in the case of ALB on Swagger/OpenAPI support, throttling etc.). Serverless is also a suitable choice for batch jobs that have to run for less than 15 minutes (limit for Lambda), as it allows the individual jobs to be scaled individually. For big data, AI/ML jobs, we still have to wait for serverless to spread. With the Lambda Layers and Lambda Runtime APIs feature, however, it is already possible to access such frameworks as TensorFlow and MXNet from within AWS Lambda. Other questions we need to ask ourselves are:
-
- Do we need access to specialized hardware for our workloads? With Lambda, for example, we cannot access GPUs, which is the case with EC2 instances and containers.
- Do we need constant high performance (e.g. response times below 100 ms)? It is essential for certain applications such as game platforms and online auctions. With so-called cold starts and depending on the choice of programming language, such response times are constantly difficult to achieve. When we talk about platform limitations, we will take a closer look at this point.
- Do we need a constant high throughput? Lambda’s network bandwidth is limited (an order of magnitude less than a single modern SSD) and is shared by all functions on the same VM
- Do the Lambda functions have to communicate with each other? Functions are not directly accessible via the network, but must communicate via an exchange service. This adds an overhead in the form of serialization and deserialization of the payload and can affect performance depending on the size of the payload.
We can see that there are both very suitable use cases for serverless as well as cases where serverless is not yet fully developed. However, the trend in recent years has been for vendors (such as AWS) to make serverless services available for more and more use cases by constantly improving and providing new features.
Platform and service restrictions
The next point is to understand the platform and service limitations. Every AWS service has a long list of restrictions, and serverless services are no exception. These can be divided into “soft limits” (you can make a request to AWS and the limit is usually increased) or “hard limits” where an increase is not possible. These limits are often cited as a reason not to go serverless. But in most cases the restrictions have their justification: For example, the maximum value for the API Gateway Integration Timeout is 29 seconds. This means that the Lambda associated with it must no longer be running. But if we consider that we use an API gateway mainly for public-facing APIs, the interface should provide an answer in a few seconds. Lambda has a maximum runtime of 15 minutes. If this is not sufficient, e.g. if it is a long running job, you should use either AWS Batch or AWS Step Function instead. In addition, you may currently allocate a maximum of 3 GB memory to a Lambda.
Another often overlooked limitation is the number of Lambdas running in parallel per AWS account. The value varies depending on the AWS region and is currently between 500 and 3000 (when Lambda Service was released, the initial value was only 25). This is a soft limit that can be increased. However, the other hard limit comes into play: If the soft limit of the region is exceeded, only a maximum of 500 Lambdas per minute are added. If you want to reach 10,000 instead of 3,000 parallel executions, it takes another 14 minutes. You can also set a concurrency limit at the level of each individual Lambda function. However, the sum of these values for all lambdas must not exceed the account limit. This gives you more control, but you should remember not to get into a situation where this number is insufficient and throttling at the Lambda level occurs. To avoid throttling, you can use Kinesis as a buffer.
Another restriction that provides much food for thought is the so-called cold start. Here, one should consider the situation with and without the use of VPC. The use of some AWS services within a Lambda, such as ElastiCache, Elasticsearch, RDS (relational databases) and Aurora (with one exception, but more about that later) requires the configuration of a VPC. You can read more about this topic here. As a rule (e.g. for asynchronous communication or for non-performance-sensitive applications), and especially without a VPC, cold starts have no negative effect. Where it is sensitive, the problem can be mitigated by calling the Lambdas periodically to keep them warm.
Nevertheless, AWS environments are sometimes completely cleared up and the first time a Lambda function is executed in the fresh environment, a cold start occurs again. Considering the sensitive peaks (e.g. when a newsletter with discounts goes out at 8pm to millions of users) and wanting to ensure that so many requests can be processed, AWS has announced a new feature called Provisioned Concurrency. It also helps to reduce cold starts for programming languages like Java (which are much more common than JavaScript). However, using the feature means certain costs, even if you do not use the provided capacity. So the serverless promise – “pay only for what you use” – is not kept at this point. From our point of view, this is another option that results in this trade-off.
With the use of VPC the situation is as follows: Not long ago, this extended the cold start by up to ten seconds. This is how long it took to create and assign Elastic Network Interface. Furthermore, it was possible to run into other platform restrictions. A no-go for most users. Recently, VPC networking has been dramatically improved with AWS Hyperplane. Now we are talking about less than a second for the additional overhead of using a VPC. In our experience, a VPC is especially needed when using Lambda together with relational databases. They are still popular and have their specific fields of application. Independent of the already significantly reduced VPC cold start overhead, the use of the relational database in a serverless environment poses further challenges. For short-lived Lambda functions with a runtime of a few hundred milliseconds, the overhead when establishing a connection or managing the connection pool is clearly too high. For the unclosed database connections, it threatened to exceed the limitation on the maximum number of connections per RDS cluster. AWS offers two approaches to solving this problem:
- Using the Data API, which allows you to access the database via HTTP (like DynamoDB) and to dispense with VPC and connection pooling. However, Data API is only available for Aurora Serverless for MySQL and PostgreSQL databases. You can read more about how this API feels and how powerful it is for MySQL here.
- The recently introduced RDS proxy should alleviate the connection pool problem when using a VPC. At the moment this service is still in preview and only available for RDS MySQL and Aurora MySQL. But PostgreSQL support is expected soon. Those who already know PgBouncer for PostgreSQL will notice a certain similarity to the RDS proxy.
The next point, corporate knowledge, is certainly the most sensitive. We believe that it is not decisive which paradigm is used, and that success or failure instead depends primarily on people. With almost every paradigm change, it is necessary to do certain things completely differently and to change some things that have been successfully practiced for decades because they no longer fit the direction. It is the task of strong leadership to take the people in the company along on the new path, to point out advantages and new perspectives and to train or even retrain them accordingly. It is no different with serverless. At this point, we will highlight the changes that serverless brings with it for developers and classic system administrators.
We ourselves work in a company where we have implemented a lot of backend with Java (our developers have over 20 years of programming experience in this language) and the Spring Framework. Our first foray into AWS and the first serverless projects at the beginning of 2018 posed challenges for us. First of all Java is known as a language that has a high startup time and a high memory consumption. These are exactly the things that negatively influence cold starts and costs.
AWS only supported Java Runtime 8 until November 2019, but this has been supported since 2015, while other cloud vendors have only supported Java 8 since 2019 and some are still in preview. With Java 8 you don’t get a module system (jigsaw), no JLink (to deploy only the necessary modules), and also no GraalVM with AOT compiler to reduce startup time and memory consumption. In addition, the Spring framework does a lot at runtime and via reflection; for short-lived Lambda functions, an expensive pleasure. Not every developer with a lot of experience in Java and Spring feels comfortable pressing a reset button in such a situation and saying: “I’ll go a different way, take JavaScript or TypeScript and practically start from scratch”. However, this step is sometimes necessary. We have therefore taken a much broader approach to the choice of programming languages. So we continued to use Java for some Lambda functions when it suited the use case or when the productivity of the developers was more important to us. As of November 2019, Lambda also supports Java 11 and we have the above-mentioned possibilities at our disposal. There are frameworks such as Micronaut and Quarkus, which have successfully met the challenges of Java in the serverless environment. Another challenge is that the changeover to NoSQL databases like DynamoDB is also very challenging. DynamoDB does not have aggregates (but DynamoDB streams) and table joins for good reasons. To be successful with NoSQL databases, you have to practically forget the best of the world of relational databases (e.g. normalization) and learn new things. Here we refer to a presentation by Rick Houlihan. As we mentioned before, AWS has recently done a lot of work with Aurora Serverless and RDS Proxy to make it possible to use relational databases in serverless as well.

Develop state-of-the-art serverless applications?
Explore the Serverless Development Track
The last point we want to reiterate here is that developers must internalize the mindset of writing as little code as possible and avoiding unnecessary complexity. “Optimize for maintenance” must be the motto. With serverless, the incentive must be to complete the task with as little custom code and as much use of managed services and configuration as possible.
The situation with classic system administrators is no less challenging. There is no access to the server, no agents can be installed, many things are suddenly different. However, there are enough challenges in the serverless environment where system administrators can contribute to the solution with their valuable knowledge and experience. These include:
- Comprehensive monitoring, tracing and alerting. Rarely is the application completely serverless, so these concepts must be standardized for the entire application.
- Chaos engineering, site reliability engineering practices, and game day implementation.
- Infrastructure as Code (IaC) and infrastructure testing. Especially if the application is not completely serverless, and different tools and frameworks are used across several teams (e.g. CloudFormation, CDK, Serverless Framework, SAM, Amplify, Terraform), the prerequisites must be created to be able to set up the complete environment with IaC.
- Understand the limitations of the individual AWS services and make suggestions on what the team should focus on for specific tasks, and provide criteria in good time when (e.g. at how many calls per second) the decision should be discussed again and possibly reconsidered. The best example is when I use AWS EventBridge, SQS, SNS or Kinesis or a combination of these services.
As we can see, there are still enough challenges. But the boundaries between Devs and Ops are blurring with serverless. In our opinion, this can only work well if both work together in a team on a product, feature or service, pursue common goals and learn from each other. And above all, to take on new challenges. Developers must also take on more Ops tasks, such as IaC, CI/CD, observability, etc. Joint responsibility for costs is also part of this, because it is possible to track exactly what the costs per AWS service are and even what the operation of individual features and services costs, in order to then make targeted optimizations.
Cost structure of serverless applications
Serverless is often associated with cheap infrastructure. In fact, the computing time of a function in the serverless model is more expensive than on a VM. Only with the right workflow in combination with the pay-as-you-go model can the serverless variant be more cost-effective.
Let’s take a closer look at the cost structure of AWS Lambda. AWS Lambda uses a pay-as-you-go model. This means that you only pay for the actual use of the resource. This makes serverless extremely cheap for a low load that occurs only sporadically. Especially new projects, which initially have a low load volume, can benefit from this. An AWS lambda function costs just 0.0000002 cents per call. That is 20 cents for one million calls.
However, the actual cost drivers for AWS Lambda are the runtime and the allocated main memory, which is additionally billed. The runtime and the allocated main memory are billed in the unit gigabyte per second, that is, the allocated main memory multiplied by the seconds that the function runs. This means: For a Lambda that runs for one second and has an assigned GB, you pay one GB/s. A GB/s costs 0.000016667 US dollars. So for one million calls to a lambda with, for example, 256 KB and a runtime of one second each, an additional 4.16 US dollars must be paid for the GB/s price. This is far more than the 20 cents that have to be paid for the calls alone.
How high are the costs of serverless compared to the classic infrastructure?
A direct comparison shows that serverless is initially more expensive. Figure 3 shows the costs of AWS Lambda compared to instances from the M5 General Purpose instance family.
AWS organizes instances into instance families, with each instance family having different performance characteristics and defining its own price class. Within an instance family there are EC2 instances with different main memory configurations. If you look at the price tables of an instance family, you will notice that the price for an EC2 instance within an instance family grows linearly with the configured main memory and is billed every second. This means that the GB/s price can be calculated for instances within an instance family. If the GB/s price for an instance is known, the costs can be compared directly with AWS Lambda. As Figure 3 shows, the costs for AWS Lambda are about four times higher than the costs for instances from the M5 General Purpose Instance Family. If you reserve an instance for one to three years, it can even be up to 70 percent cheaper. The price difference to AWS Lambda increases enormously again. The longer you plan ahead, the cheaper it becomes. However, you lose flexibility as a result. The problem is: Most workflows have a very variable load behavior that is not predictable. For this reason, servers are usually over-provisioned, which often cancels out the cost advantage or even turns it into the opposite. With serverless, however, automatic scaling and high availability are already integrated and coupled with a pay-per-use model. Since you only pay for actual use, the costs scale automatically with the load that occurs.
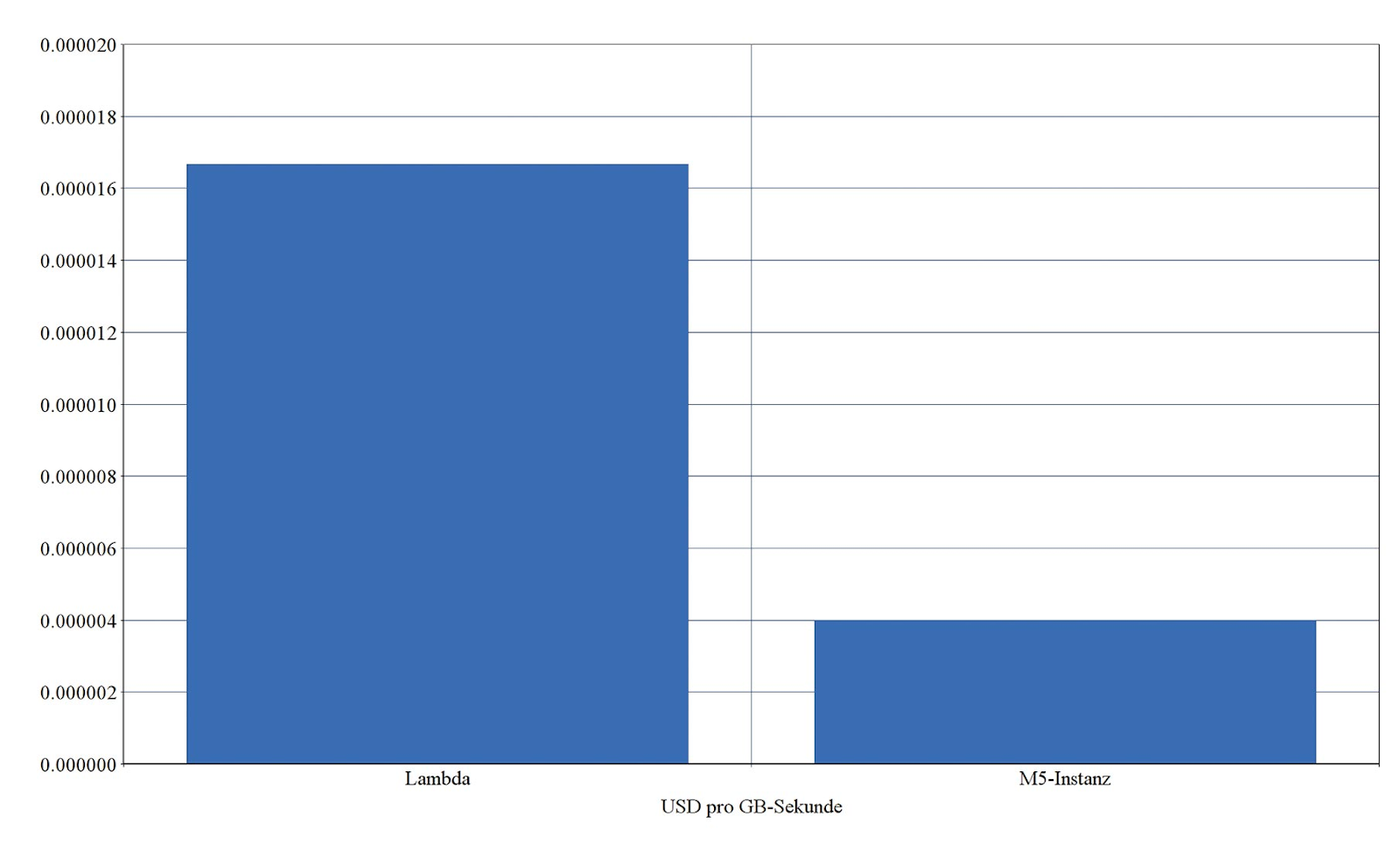
Comparison of costs in US dollars per GB/s between AWS Lambda and an M5-EC2 instance
When considering the costs, however, it must be taken into account that the costs for AWS Lambda are only a fraction of the total costs of a serverless application. In most cases, services such as CloudWatch for logging and monitoring, API gateway, data storage with S3 or DynamoDB (to name just a few services) and data transfer make up a much larger share of the total costs when aggregated. The API Gateway alone, which is often used to integrate an API with one or more Lambda functions, has a cost of $3.50 per million calls, so that for API-heavy applications the cost of the API Gateway is usually much higher than the cost of the Lambda functions. As with all applications, it is therefore important to always consider the overall context. The fine-grained cost structure of a serverless application makes it particularly difficult to estimate costs in advance on the one hand, but on the other hand it offers the possibility to break down and analyze running costs of individual workflows down to individual function calls. This makes it possible, for example, to pass on a pay-per-use cost model to customers in a granular way. This practice, called FinDev, is a trend that has only become possible through serverless.
Platform and tooling maturity
With serverless, not only can small projects be set up, but also large, complex applications can be implemented today. Such distributed and event-driven architectures, which are designed for a high load volume, require good logging and monitoring.
AWS offers the X-Ray service for distributed tracing. Although this service is easy to use, it quickly reaches its limits for more complex applications, since tracing via asynchronous calls is only supported for certain services. If an asynchronous step runs over an unsupported service, a new trace begins from the X-Ray view. Although the problem can be solved by extending the implementation itself, the basic idea of a serverless application is actually to implement as little as possible yourself. External providers such as Epsagon or Lumigo have already recognized the gap and are trying to jump on the monitoring bandwagon. While more expensive than the AWS-native solutions, the external vendors’ solutions have a much wider range of features that go beyond simple monitoring, such as cost breakdown for individual requests to fault diagnosis.
CloudWatch, the AWS-native solution for logging and monitoring, also already offers extensive possibilities. For example, CloudWatch Logs Insights can be used to perform an aggregated search across multiple Lambda log streams. If you prefer to use third-party solutions such as Elasticsearch or Loggly, the logs can be streamed to the providers in real time. CloudWatch also offers the option of displaying metrics visually and defining alarms for specific thresholds.
Another important aspect is the provisioning of the infrastructure via IaC. One of the best known tools in this area is the serverless framework, with which we have had very good experience. The tool not only works with AWS, but is cross-platform. The framework is especially interesting because it is very easy to extend with plug-ins. This is an essential difference to the AWS-own tool SAM, which works similarly to the serverless framework, but does not support extension by plug-ins.
A new star in the AWS provisioning sky is the Cloud Development Kit (CDK). The configuration is not done in YAML, but programmatically. Different languages like Java or TypeScript are supported, so that developers can work in their familiar environment. The CDK has only been available as a stable release for a few months, which is still noticeable in the tool and documentation.
The AWS Amplify development platform goes one step further: The development platform is a so-called Opinionated Framework, i.e. the project structure is more or less predefined and can be set up initially by means of a scaffolding. Preconfigured libraries and UI components are also provided. Thus, IoC can be reduced to a minimum.
Even though the tooling for serverless is still in its infancy – which is due to the still very tender age of the technology – there are already a multitude of possibilities to ensure the operation of a serverless architecture.
Learn more about Serverless Architecture ConferenceSTAY TUNED!
Conclusion
With serverless in combination with Managed Services, speed and new momentum can be brought to development. It eliminates much of the complexity of provisioning, maintaining and scaling servers. And if existing, i.e. Managed Services are used, employees can concentrate on the development and maintenance of the core domain.
But serverless is not always the cheapest option. Depending on the workflow, the costs for the infrastructure can also be higher. But more important than the infrastructure costs are the total cost of ownership. Because even if the infrastructure costs are higher, the speed gained in development can compensate for or exceed them.
Serverless does not fit every application. Serverless platforms still have many limitations. For example, if the application has special performance requirements for the file system or requires access to the GPU, VMs or containers must still be used. It is therefore important to understand the application requirements and the possibilities and limitations of FaaS platforms before deciding on a serverless approach.
However, the biggest challenge in implementing serverless is not technical. Serverless requires a rethink in development and operation. As long as ways of thinking and old habits remain the same, it will be difficult to establish serverless in the company. But once the hurdles have been overcome, not only new possibilities open up: Serverless development is also a lot of fun!





