
Lambda is a serverless compute platform first made available to customers in 2014. Since then, it has grown to have over 1 million active customers, and more than 10 trillion requests a month. Lambda allows you to run code without provisioning or managing any servers or infrastructure. You only pay for Lambda when your code is executing, and you don’t pay for it when it’s not in use. When traffic to your application increase, Lambda will automatically scale to meet the demand, and availability and fault tolerance is built in.
Learn more about Serverless Architecture ConferenceSTAY TUNED!
Serverless Characteristics
Unlike using virtual machines or container platforms, when you use Lambda, AWS manages much more of the infrastructure. Regular maintenance chores, such as patching of the operating system and Java runtime, are done automatically with no interruption in service or downtime. AWS will manage the rotation of host machines for patching when required while maintaining the capacity required to meet your traffic requirements. When your Lambda function runs for the first time it creates a lightweight virtual machine (VM) called a microVM using the Firecracker open source project on a suitable host, your application code is put onto the microVM and loaded into the Java virtual machine (JVM). Your code is then executed. You pay a for just the period it takes for your code to respond to the request. You don’t pay for any idle time between request. To keep the application programming model as simple to scale as possible, each virtual machine only processes one request at a time. As traffic to your Lambda function increases, more virtual machines will be allocated. Having lots of small units of compute means that any single failures have a minimal effect on the total system. If there is a wider issue with an AWS availability zone, then Lambda will automatically shift your requests to other availability zones.
Pay per use pricing isn’t just useful for production, it is also useful for the other environment you have as part of your software development life cycle. Often there is a trade-off between the expense of additional environments and the increase in productivity. You can deploy as many copies of your Lambda function as you like, and while it’s not being used, you do not pay for it. Each developer of a team can have their own copy of an environment so that they can work in isolation without effecting or being affected by others. Environments which are used to test non-functionality requirements like the amount of load which can be handled, can be particularly costly. The environment has to have the same capacity as production, but is relatively rarely used. Now you can have benchmarking environments which have the same capacity as production and only pay for the specific requests made.
This also has the additional benefit that making proof-of-concepts and experiments is quick and easy without compromising on quality. If they have low traffic, then you don’t pay for over provisioning, and if they are successful and bring more traffic, then Lambda will automatically scale to meet demand. High availability, fault tolerance, and load balancing are all built into the service, meaning that you don’t have to spend important developer time working on these difficult architectural problems early on when there is no certainly that the project will be a success. This allows teams to spend more of their time being innovative and trying new things.
Security
At AWS, security is always job 0 and Lambda is no different. Although many customers use the same hosts, AWS has controls in place so that each function is isolated from each other function.
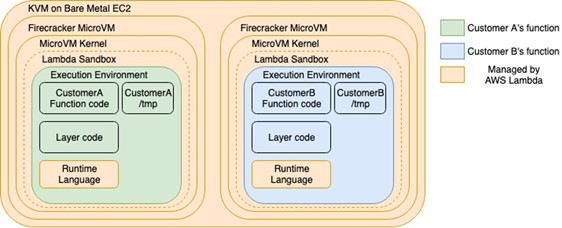
As with all good security, this happens in layers. Customer’s code is always run in a separate virtual machines. Linux kernel features are used to limit functions’ access to CPU and memory resources. Firecracker features are used to limit access to block device and network device throughput. The execution environments have restricted access to which system calls can be used.
Because AWS manages the Java runtime and how your code is loaded, it also allows further code level security measures. In December 2021, AWS applied a change to the Lambda Java runtime that helps to mitigate the issues in CVE-2021-44228 and CVE-2021-45046 also known as Log4Shell. Although it is still important for customers to update their 3rd party dependencies, in this case Lambda could give an extra layer of protection while changes were being made.
Architectural Differences
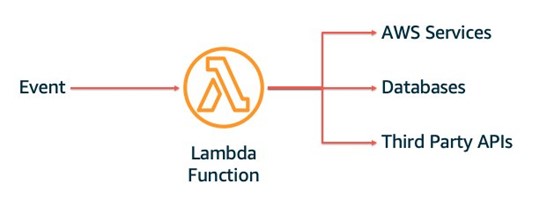
Unlike VMs and containers which start-up process to poll a queue or listen to a port, you can only interact with Lambda via its API. Lambda has an is event-driven programming model. Lambda can receive events from many native AWS integrations. For messaging workloads, there are integrations with Amazon Simple Queue Service (SQS), Amazon Simple Notification Service (SNS), ActiveMQ and RabbitMQ, for streaming workloads Kafka and Amazon Kinesis and for HTTP workloads Application Load Balancer (ALB) and Amazon API Gateway. You can also invoke a Lambda function directly with the AWS SDK or CLI. Events are JSON payloads passed to your code.
This programming model is the key things to understand as you’re working with new Lambda applications or migrating existing applications to Lambda. It will affect how observability tasks like logging, metrics and tracing work, it might also affect how you manage application configuration and secrets. In most cases, the changes required are minimal and follow the common methodology of twelve-factor applications[2].
All access to Lambda functions is via a single API called the invoke API. This is how your code receives events. No individual microVM hosting your code is addressable. This means that any integration which you have which polls an application server endpoint will need to be refactored. A common example of this type of integration is Spring Boot actuator metrics. This feature of Spring Boot creates a HTTP endpoint which responds with application metrics. Your observability platform periodically polls all the known instances of your application for the data exposed.
With Lambda, the microVMs which run your code are not directly addressable, so can’t be polled for data. Instead, your Lambda functions should push metrics to your desired location. The Lambda service automatically produces function level metrics such as number of invokes, duration of execution, number of errors and more. You can find more information about the metrics produced by the service under Working with Lambda function metrics of the Developer Guide[3].
To record metrics which aren’t made available by the Lambda service, such as your business specific metrics, you can create your own custom application metrics into CloudWatch. The best practice way to do this is with CloudWatch Embedded Metrics Format (CloudWatch EMF). This allows you to push metrics from each invoke of your Lambda function asynchronously. To do this, you log a JSON object following the EMF specification to standard out. This is processed by CloudWatch separately from your use of Lambda and it creates metrics on your behalf.
If your application follows the twelve-factor applications pattern of logging to standard out, then when you deploy your application to Lambda it will automatically ship those log messages to CloudWatch. If your application is currently logging to a single or multiple log files, then your logging will need to be updated. There is no way to address a Lambda microVM, so it isn’t possible to retrieve a log file from it. Normally, this is a very easy change to make to direct log output to standard out instead of a specific file.
If you are already using a 3rd party observability platform, you can directly integrate with them using Lambda extensions. Check the Lambda extensions partners for a full list[4].
Getting Started
At its simplist, you can write a Lambda function as shown.

A class which implements the AWS RequestHandler interface and implements the handleRequest method. It receives an object which represents the event and a context object which contains information about the environment in which it is running in. Java object representations of many native AWS integrations are available in the events library com.amazonaws:aws-lambda-java-events:3.11.0[1]. For example, you could write a REST API by integrating API Gateway with Lambda. Your Lambda function would receive an event which represents a HTTP request. It would have all the typical information such as path, headers, body. You would write your business logic to react to that request and return a response. The Java objects APIGatewayProxyRequestEvent and APIGatewayProxyResponseEvent are available to make this simple.
Following the same pattern, you could also make a Lambda function to process messages from a queue. You could integrate Lambda with a cloud native queue like SQS or an open source alternative like ActiveMQ. Your Lambda function would receive an event which represented the message format of the producer. More Lambda function microVMs will be automatically created to handle increases in message volume. Lambda also supports batching for some of its integrations, allowing you to further optimize your costs by processing multiple messages in a single invoke.
If you are new to building with Lambda and want to get started quickly then I can recommend the AWS Serverless Application Model (AWS SAM) [5]. SAM comes with a CLI, and using the init command, you can generate a variety of working examples and the infrastructure code to deploy them. You can have a working example in minutes.
Migrating Existing Applications
You may have an existing HTTP microservice written in an application framework such as Spring, Jersey or Wicket and wonder if you can easily migrate this to Lambda. This is a valid question. The programming models are different. Most likely, this application would use Netty or something similar to run a server and listen to a HTTP port, which is not possible with Lambda.
AWS has an open source project which will allow these applications to run on Lambda with minimal changes. The aws-serverless-java-container project is an adapter for applications which are written for the server model to be run with the Lambda event model. It manages the conversion of the JSON event object to a HTTP request, which the Java framework recognizes. This allows you a simple way to take existing applications and gain the benefits of Lambda without a large refactor.
Performance Optimizations
When you invoke your Lambda function, you’ll see that the latency of the response has two different performance characteristics. Most of your requests will be quick, and a small percentage will be slower. This is because of the architecture of Lambda functions. On the first invoke of a Lambda function or when Lambda needs to scale your functions capacity, it needs to create a new microVM and load your code onto it. This is commonly known as a cold start. Once that microVM is ready, it will process requests one at a time. This is called a warm start. Performance optimizations for Lambda focus on making the cold starts as fast as possible. The changes fall into two sections, changes that you can make to the Lambda function configuration and the changes you can make to your code.
Configuration Optimizations
You can configure the amount of memory allocated to a Lambda function from 128MB to 10GB. The CPU allocation is proportionally linked to the memory allocation of the function. Java uses a disproportionally large amount of CPU at startup to compile classes from byte-code to native machine code. This means that if a Lambda function is starved of CPU, it will dramatically increase first invoke latency. If you are unsure of the amount of memory to allocate, start with 2048MB and test values above and below.
Lambda allows you to set JVM configuration flags by using the environment variable JAVA_TOOL_OPTIONS. For the vast majority of applications, you will want to change the default tiered compilation behavior.
JAVA_TOOL_OPTIONS="-XX:+TieredCompilation -XX:TieredStopAtLevel=1"
This JVM flag tells the compiler to use the C1 compiler to compile the byte-code to native machine code, but not to do further profiling and optimizations for the C2 compiler. Lambda wants to minimize all additional work which is done at the beginning of processing. This change might appear that you are exchanging peak performance for faster first invokes. For the vast majority or cases, that isn’t true because the C2 compiler needs a relatively large amount of requests in order to further optimize what the C1 compiler has already done. If your function is running for minutes or is repeating the same piece of code thousands of times within the same execution. An example would be running Monte Carlo simulations. Then this optimization might not be suitable.
Lambda SnapStart
SnapStart is one of the newest features to be launched by the Lambda team, and its purpose is to improve first invoke latencies by 10x. SnapStart is a feature which you can enable on your Java 11 functions in combination with Lambda versions. Lambda versions are, as you might expect, immutable versions of your Lambda functions configuration and code at a particular time. When a version is created for a function with SnapStart enabled then the initial part of the Lambda process happens as normal. A new microVM is created on a suitable host machine, and your code is loaded into the JVM. At this point, a snapshot of your microVM is taken, the complete image is encrypted and stored. The image holds all the information about any running process, their memory, and the complete file system. It is then broken into parts and loaded into a multi-tiered cache for fast retrieval. Once this process has completed, future instances of your Lambda function can be created by loading the image from cache. This often happens in 200-300ms and is much faster than the standard mechanism. There is no additional cost for using SnapStart. The Lambda developer guide has a complete reference guide to SnapStart if you would like to know more[6].
Code Optimizations
STAY TUNED!
Learn more about Serverless Architecture Conference
Reducing the amount of code loaded at startup is a key consideration when using Lambda. Any code that might have been migrated from a previous application should be checked to see if it is see applicable to be used with Lambda. Endpoints used for metrics or health checking are examples that can be removed or disabled when deployed to Lambda. 3rd party dependencies often have alternatives which provide most their functionality with a smaller CPU and memory footprint. An example of this would be Jackson databind and Jackson-jr. Also consider if you need all the functionality of a logging framework like Log4J, can you use something simpler like slf4j-simple.
Learn more about Lambda
I hope you’ve found this article useful. If you would like to learn more about Java and Lambda, then AWS has produced a hands-on workshop you can try for free. You can find the step-by-step guide at https://catalog.workshops.aws/java-on-aws-lambda/
It includes sections on how to migrate Spring Boot applications to Lambda, performance optimizations and a complete SnapStart walkthrough.
[1] https://github.com/aws/aws-lambda-java-libs
[3] https://docs.aws.amazon.com/lambda/latest/dg/monitoring-metrics.html
[4] https://docs.aws.amazon.com/lambda/latest/dg/extensions-api-partners.html
[5] https://aws.amazon.com/serverless/sam/
[6] https://docs.aws.amazon.com/lambda/latest/dg/snapstart.html




