A picture is worth a thousand words – and when talking about the differences between established large companies and start-ups, the image of sluggish supertankers and agile, small speedboats regularly comes up. So far, so good. But if you look at the reality, you see that most start-ups are indeed small boats, but the question of manoeuvrability and speed remains partly unanswered. The real will to launch a first product as quickly as possible is often missing. One of the reasons could be that although many young companies come up with fresh product and service ideas, they often have little experience with product delivery, i.e. the simple implementation of your many ideas.
There are countless technologies, tools and methods that can help a start-up achieve extreme speed. But it takes hard work to properly prioritise, select, apply, learn and embed what you learn in the company and in your minds. In a start-up, this is the joint task of product and development managers. Take the widely discussed topic of serverless infrastructure. The advantages are obvious, but how do you achieve the goal of establishing such an innovation in the company in the most targeted and smart way possible? That was and is also the goal of Laserhub GmbH, a start-up founded two years ago in Stuttgart. As founders, we developed an automated digital platform for order management in the sheet metal industry. In order to grow quickly with this, to react quickly to trends and to integrate new features, we have dealt intensively with the topic of serverless. It is important to know that we were able to establish a functioning product on the market after only three months. In the meantime, we are looking at a very broad customer base, of which we are mighty proud. However, since we want to continue to be open to experimentation – with the highest reliability for existing customers – a certain tact is required in the selection, conception and implementation of new technologies. One of these topics was serverless and more specifically serverless framework. We see great opportunities in this and have therefore looked at the topic in detail or implemented it directly.
STAY TUNED!
Learn more about Serverless Architecture Conference
Focus on added value and feasibility
You can spend countless weeks on the topic of serverless, as the playing field is now immense. However, we are not a research department, but a fast-growing start-up with limited resources and very ambitious growth plans. To approach the topic, we have therefore set ourselves concrete goals:
With a serverless solution, we eliminate an acute and important problem (direct added value).By introducing the solution, we initially do not change anything in the existing deployment (little distraction). We use the solution in productive operation so that we can learn from our own experiences (mindset of continuous improvement). The solution is scalable and can be applied to other contexts (scalability). So we have tackled a current problem: how do we react to changes in connected third-party systems? Sure, WebHooks are obvious, but how do we guarantee that the respective endpoints on our side are always available, react to errors in processing if necessary, and also offer different authentication options? All this under the premise that a third-party provider sets the rules for how it wants to integrate. In our case, it was about an API for booking parcel services and we wanted to tackle this problem with new technologies.
The right tooling
Usually, you don’t want to spend too long choosing the perfect tooling. For us, Serverless Framework was a good choice because it is cloud agnostic, has a very broad feature set and seems to be sufficiently documented. Moreover, we were aware of some references that have Serverless Framework in use. The Serverless Framework setup is really very simple. First of all, it is necessary to install the CLI, get to know it and start the first attempts. In order to be able to deploy the first tests directly, you have to log in to a cloud provider with an existing account, in our case AWS. This all went very well according to the instructions.
Of course, the Serverless Framework initially assumes that the user connects to a singular cloud. A number of cloud-specific boilerplates are available for this purpose, which directly provide the respective configuration. Then you can get started and deploy a “Hello World” function. A simple CLI command takes care of the build and deployment of the local configuration to the cloud:
$ serverless deploy
You immediately get a feel for the work the framework does. All cloud provider-specific connections and dependencies in the configuration are taken away from you. The easiest way to see this is to log into the cloud console (i.e. the web UI of the respective provider) and visually see which resources are now connected together and how. Goal achieved: Infrastructure as Code – done.
From setup to application
In the next step, we looked at the serverless.yml in detail. More complex configurations for infrastructure and serverless business logic are stored in this file. Now you have to know that Serverless thinks in functions, so we always start with a Serverless Function (or, in AWS slang, a Lambda). This gets a name and later also a business logic. But how is it first addressed or triggered? This is where events come into play. There are many different ways to address our function.
API Gateway
Since we want to reach our goal with the help of WebHooks, we rely on a REST endpoint. For this we need to define an HTTP event:
events: - http: path: hooks/shipping method: post
The implementation is then straightforward. We define a URL and the HTTP method. That is all. But you should be aware of what happens in the background. With a simple serverless deploy, we build an endpoint in the AWS API Gateway in the background that is immediately accessible and functional. Side Fact: API Gateway provides out of the box testing and staging environments. Figure 1 shows the result in the console.
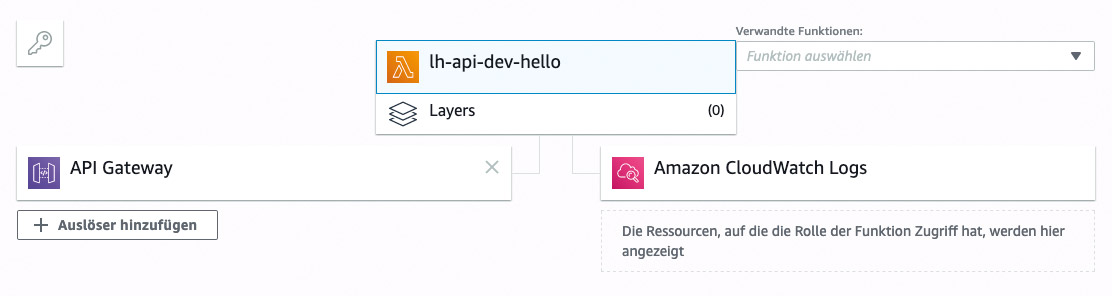
Fig.1: API Gateway result in the console
The function stub is also quickly implemented. In the Functions folder we place a file with the appropriate name and provide a function with the necessary API. This function can now be used as an entry point for any business logic.
module.exports.handler = async (event, context, callback) => { }
WebHook and integration pattern
Thus, we have made all preparations on the infrastructure side to define and implement the WebHook integration. To do this, we store our URL (from the API gateway) in the configuration of the SaaS solution. As a result, an HTTP request is triggered to the configured URL whenever the status changes. But how does the third-party provider want to authenticate itself? In this particular case, it is very simple via a static token in the URL. This is not a standard authentication. The function therefore takes care of parsing the token itself.
However, it is obvious that we do not want to store the configured tokens as plain text. Accordingly, we use environment variables that we can call in the function. For this, Serverless Framework offers the option to store key-value pairs in env.yml. Listing 1 shows an example excerpt and how it is possible to create global as well as environment-specific variables.
Listing 1 Globals: &globals foo: "BAR dev: <<: *globals TOKENS: "egknk8ax5f5weysq9ay4" prod: <<: *globals TOKENS: "0cg5ycxq1i6yis2dknyd"
So the endpoint is there, authentication is possible – what remains is the logic. In this case, we have decided on a further abstraction. Our function sends a message via an AWS SQS queue and that’s it. The existing app serves as a message handler and processes all incoming messages. Depending on the message type, different processes are handled. This solution offers the following advantages:
Almost every backend can handle corresponding queues (no lock-in). If it is not possible to process the message at the current time, we can use retry strategies.
Our workers are implemented in the existing repo and have access to all existing resources and services. So I don’t have to do and maintain an expensive migration of the business logic into the serverless function.
In listing 2 we see the handler function and in listing 3 the lib for the queue handler.
Listing 2 const jsonResponse = require('../lib/jsonResponse') const queueHandler = require('../lib/queueHandler') module.exports.handler = async (event, context, callback) => { const tokens = process.env.TOKENS.split(',') if (event.queryStringParameters && event.queryStringParameters.token && tokens.includes(event.queryStringParameters.token)) { return queueHandler.sendMessage(shippingUpdate, event.body) .then(data => { return jsonResponse.ok({message: 'success'}) }) .catch(e => { console.error(e.message) return jsonResponse.error({message: e.message}) }) } else { return jsonResponse.unauthorized() } }
Listing 3 const AWS = require('aws-sdk'); const sqs = new AWS.SQS({ region: 'eu-central-1' }) const sqsQueueUrl = process.env.AWS_SQS_QUEUE_URL async function sendMessage (taskName, body) { const params = { MessageBody: JSON.stringify({taskName: taskName, body}), QueueUrl: sqsQueueUrl } return sqs.sendMessage(params).promise() .then(data => { console.log('Success sending message', taskName, data.MessageId) return data }) .catch(err => { console.log('Error sending message', err) }) } module.exports = { sendMessage }
If you have been paying attention, you may have noticed that our function indirectly accesses another AWS resource and requires corresponding permissions (SQS Queue). A plug-in for the Serverless Framework provides the handling of IAM Roles for this purpose, and in this case the configuration also takes place via environment variables. An additional configuration of IAM Roles is possible for each event (serverless.yml):
iamRoleStatements: - Effect: "Allow" Action: sqs:SendMessage Resource: ${self:provider.environment.AWS_SQS_RESOURCE}
The implementation of the worker logic is not very spectacular, so I will spare the details here. Figure 2 shows an overview of the serverless integration pattern for WebHooks from third-party systems.
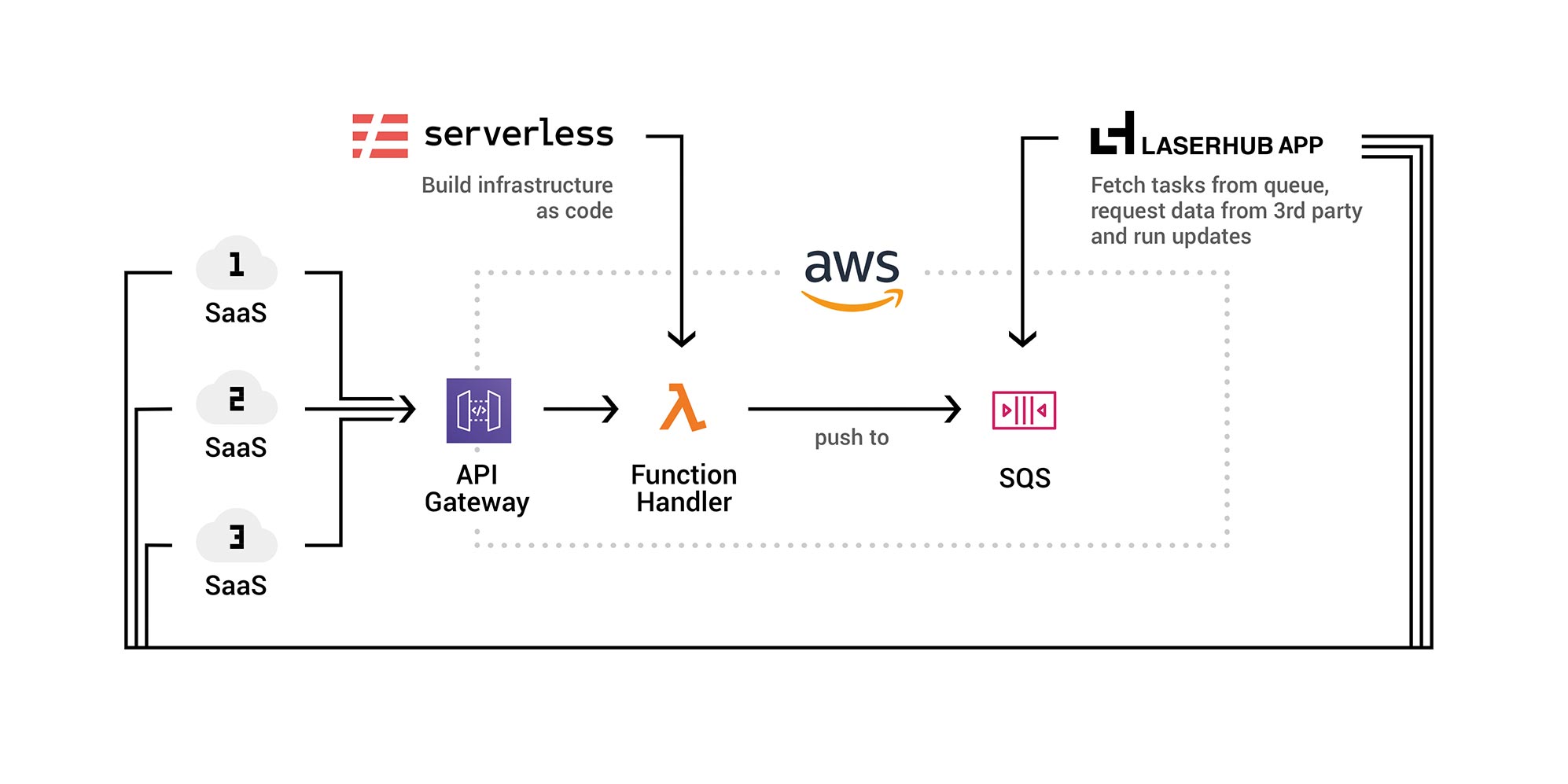
Fig.2: Serverless integration pattern for WebHooks from third-party systems
Let’s talk about one more hurdle. We need to make the API gateway accessible from the outside via a nice URL. For this purpose, too, we resort to a serverless framework plug-in: serverless-domain-manager. Through this plug-in, a domain can be configured and managed via serverless deploy.
Redirect root domain
A short note should be allowed at this point: The boilerplate configuration contains a handler for the hello function. This outputs the request input and serves as a quick orientation for beginners. However, one should not forget to define this endpoint, as otherwise important information about the AWS account is freely accessible. In our case, we opted for a simple redirect to laserhub.com (Listing 4).
Listing 4 module.exports.hello = async (event, context, callback) => { const response = { statusCode: 301, headers: { Location: 'https://www.laserhub.com' }, body: '', } callback(null, response) }
In this case, we have only changed a function and can also deploy it independently. A serverless deploy -f hello -s prod pushes the new function directly into the cloud.
Developer workflow under Serverless Framework
Recap: Our function offers the possibility to execute arbitrary Node.js code. Depending on which packages our application uses within a function, the build and thus the deployment become larger and more time-consuming. To offer a serverless developer the best experience here as well, we resort to a serverless framework plug-in one last time. Serverless Offline emulates a local AWS environment, so we can very easily develop the configuration locally before testing it for staging and then deploying live.
STAY TUNED!
Learn more about Serverless Architecture Conference
Git
Infrastructure as Code has another captivating advantage besides ease of use: all work can be cleanly versioned and managed in Git. This not only makes collaboration very easy, but also bug tracing and rollback handling can be done with a few Git commands.
That’s it. With relatively little effort and no changes to the existing architecture or business logic, we have realised a finished serverless application.
Conclusion and outlook
Even though we had to learn a few things in between, our experience with the Serverless Framework is very positive. In just two weeks, we entered the world of serverless, took our first steps and implemented a productive solution. This has been running for about six months and has been extended by an additional endpoint so far.
At this point, the necessity of many plug-ins may be critical. These are often maintained by the community, so that there is a certain risk for productive environments that they are not sufficiently maintained. The serverless idea has arrived in the development team and we are currently evaluating other areas where we can rely on serverless infrastructure. Especially for very small and independent services, it makes sense to do without any application underpinnings and run them serverless instead. We are also considering including our serverless applications in our CI/CD strategy.




